![]()
etcd不仅是Kubernetes的核心存储组件,更是当下云原生时代的存储基石之一。
etcd的诞生背景
2013年,CoreOS公司构建了Container Linux。这是一个基于Linux内核的轻量级操作系统,专注于自动化、轻松部署、安全、可靠及可扩缩性。作为一个操作系统,Container Linux提供了在容器内部署应用所需要的基础功能环境以及一系列用于服务发现和配置共享的内建工具。
CoreOS同时为Container Linux提供集群化的管理方案,用户管理应用服务就像单机一样方便。集群会部署应用服务多副本实例,满足单实例宕机的情况下,整体服务无损。因此,对于CoreOS来说,他们需要一个协调服务,用于存储服务配置信息、提供分布式锁等能力。
当时的大环境下,ZooKeeper是一个可选方案。不过在调研完ZooKeeper之后,CoreOS发现了一些限制:
- 当时的ZooKeeper不支持通过API安全地变更成员,需要人工修改一个个节点的配置,并重启进程。
- ZooKeeper是Java编写的,部署繁琐,占用资源较多。
- ZooKeeper RPC的序列化机制是Jute,自己实现的RPC API。无法使用cURL工具互动,CoreOS希望比较简单的HTTP+JSON。
综上所述,CoreOS最终决定自己造轮子。至此,etcd正式诞生!etcd的名称由来:etc(unix系统的etc配置目录)+d(distributed分布式),由此也可以看出CoreOS对该存储组件的期望和定位。
etcd的发展史
etcd的发展史主要分为两个大阶段,三个大的版本:
Prototype到Stable:
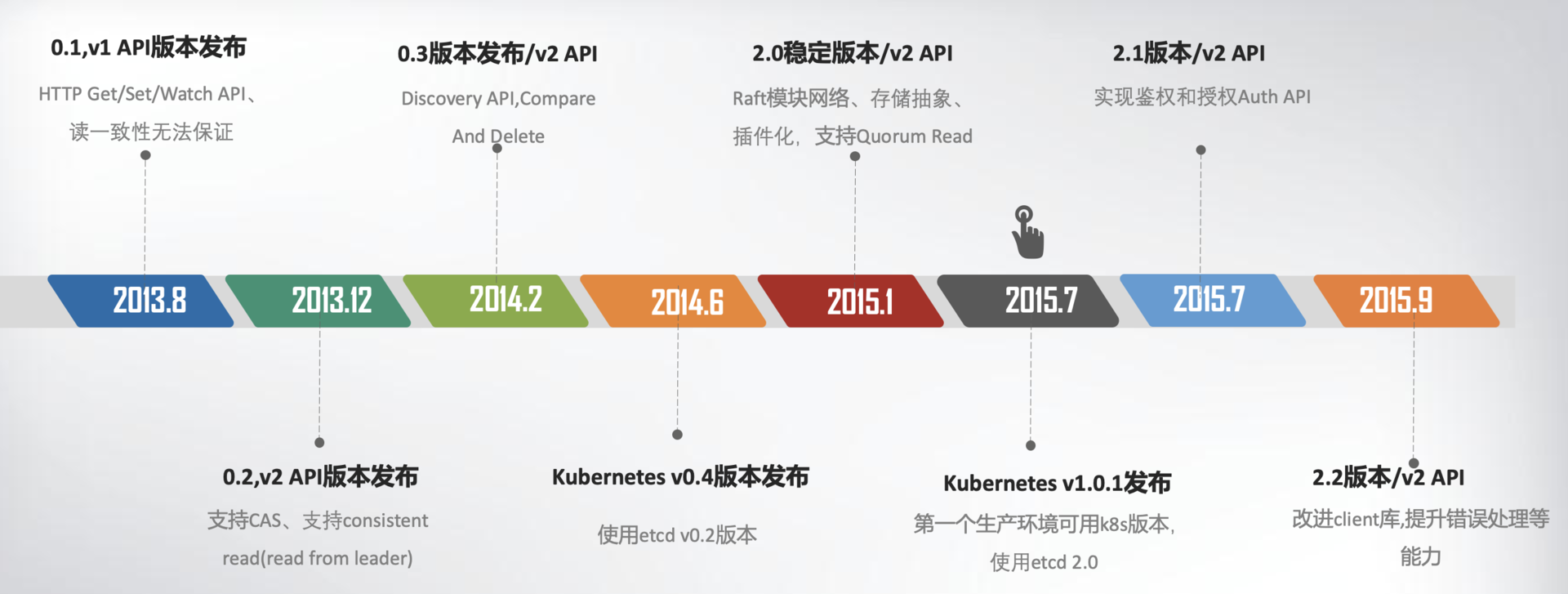
Stable到Graduated:

从时间线上,我们可以看出v1 API版本的存在周期非常短,甚至无法保证读一致性问题,基本上用作Prototype。v2 API版本和etcd v2.0的发布,则标志着etcd进入稳定阶段。而v3 API版本和etcd v3.0的发布,则正式宣布etcd进入成熟阶段。
那么,是什么因素促进etcd的蓬勃发展呢?答案是:Kubernetes!
为什么Kubernetes采用etcd作为核心存储
在《Kubernetes架构设计与核心原理》一文中,笔者概述了Kubernetes的整体架构设计。作为集群的中枢组件kube-apiserver正是采用etcd作为底层存储。
一方面,k8s集群中资源对象的创建都需要借助etcd来持久化;另一方面,正是etcd的数据watch机制,驱动着整个集群的Informer工作,从而达到源源不断的容器编排!因此,从技术角度说,Kubernetes采用etcd的核心理由有:
- etcd采用go语言编写,和k8s技术栈一致,资源占用率低,部署异常简单。
- etcd的强一致性、watch、lease等特性是k8s的核心依赖。
此外,Kubernetes选择etcd还与当时的商业竞争相关。
CoreOS是Kubernetes容器生态圈的核心成员之一,在Docker时代还曾与Docker公司密切合作。然而当Docker公司不断强化其PaaS领域的战略之后,CoreOS与Docker之间的利益冲突愈发明显。最终,CoreOS弃用Docker而选择自研容器引擎rkt,然而rkt长期在其领域被Docker全方面压制。
Docker公司后续推出的Docker Swarm彰显出它在PaaS上面的雄心壮志。因此,Google、RedHat和CoreOS联合起来,基于Google多年的容器管理系统经验架构Borg,并结合开源社区的建议和改进,共同推出开源容器编排调度系统Kubernetes。因此,etcd也作为CoreOS在Kubernetes架构中的核心组件持续优化。
etcd v2到v3的主要改进
Kubernetes的发展之迅速造就了火爆的云原生时代!与此同时,etcd v2的瓶颈和局限就充分暴露出来了。在社区的呼吁之下,etcd也积极配合用户改造优化架构,逐步向v3迈进。
那么,etcd v2的主要问题有哪些呢?
- 功能上的局限。
- etcd v2不支持范围查询和分页:随着Kubernetes节点规模的增多,集群中的资源对象也会增大。此时由于不主持范围查询和分页,会导致成本极高的全量数据拉取,甚至导致集群雪崩。
- etcd v2不支持多key事务:在某些特定的业务场景下,希望etcd的事务能够跨越多个key而存在。
- watch机制的可靠性问题。
- etcd v2底层的KV引擎是内存型:由于不支持保存key的历史版本,只在内存中使用滑动窗口保存了最近1000条变更事件。当etcd server写请求较多、网络波动时等场景,很容易出现事件丢失问题,进而又触发client成本极高的全量数据拉取,甚至导致集群雪崩。
- 整体性能瓶颈。
- etcd v2采用HTTP/1.x:由于HTTP/1.x不支持压缩机制,批量拉取较多Pod时容易导致kube-apiserver和etcd出现CPU高负载、OOM、丢包等问题;另一方面,HTTP/1.x通过长连接轮询watch事件,当watcher较多时,因HTTP/1.x没有多路复用,对服务端的socket和内存资源开销非常大。
- etcd v2为每个key设置TTL:实际的业务场景中,存在多个key共享相同TTL的场景。而针对每个key都设置TTL的做法也会显著拉低集群的负载能力。
- 内存开销问题。
- etcd v2的KV内存树和定期全量持久化:etcd v2需要在内存中维护一个树状结构来维护所有的KV信息,并且需要定期持久化全量KV树到磁盘。因此,内存开销方面是个比较明显的瓶颈。
那么,etcd v3又做出了哪些优化呢?
- 存储引擎升级为B-Tree和boltdb:解决功能上的局限、watch机制的可靠性和内存开销等问题。
- 网络框架升级为gRPC,传输基于HTTP/2.0:protobuf的压缩率更高,HTTP/2.0的IO多路复用机制减少了大量的watcher等场景下的连接数。
- 使用Lease优化TTL机制:每个Lease具有一个TTL,相同TTL的key关联一个Lease。Lease过期时删除其关联的所有key,不需要再为每个key单独续期。
etcd v3在整体功能和可用性上都得到非常大的提升,而这个过程中Kubernetes的驱动起到了核心作用。
etcd的特性
CoreOS团队在设计etcd之初,主要考虑了五大目标:
- 可用性角度:高可用。协调服务作为集群的控制面存储,它保存了各个服务的部署、运行信息。若它故障,可能会导致集群无法变更、服务副本数无法协调。业务服务若此时出现故障,无法创建新的副本,可能会影响用户数据面。
- 数据一致性角度:提供读取“最新”数据的机制。既然协调服务必须具备高可用的目标,就必然不能存在单点故障(single point of failure),而多节点又引入了新的问题,即多个节点之间的数据一致性如何保障?比如一个集群3个节点A、B、C,从节点A、B获取服务镜像版本是新的,但节点C因为磁盘I/O异常导致数据更新缓慢,若控制端通过C节点获取数据,那么可能会导致读取到过期数据,服务镜像无法及时更新。
- 容量角度:低容量、仅存储关键元数据配置。协调服务保存的仅仅是服务、节点的配置信息(属于控制面配置),而不是与用户相关的数据。所以存储上不需要考虑数据分片,无需过度设计。
- 功能:增删改查,监听数据变化的机制。协调服务保存了服务的状态信息,若服务有变更或异常,相比控制端定时去轮询检查一个个服务状态,若能快速推送变更事件给控制端,则可提升服务可用性、减少协调服务不必要的性能开销。
- 运维复杂度:可维护性。在分布式系统中往往会遇到硬件Bug、软件Bug、人为操作错误导致节点宕机,以及新增、替换节点等运维场景,都需要对协调服务成员进行变更。若能提供 API 实现平滑地变更成员节点信息,就可以大大降低运维复杂度,减少运维成本,同时可避免因人工变更不规范可能导致的服务异常。
etcd的快速体验
从0到1安装etcd集群
安装环境:Debian GNU/Linux 10
$ go get github.com/mattn/goreman
$ goreman -f Procfile start
etcd write
$ etcdctl put hello world --endpoints http://127.0.0.1:2379

etcd read
$ etcdctl get hello --endpoints http://127.0.0.1:2379

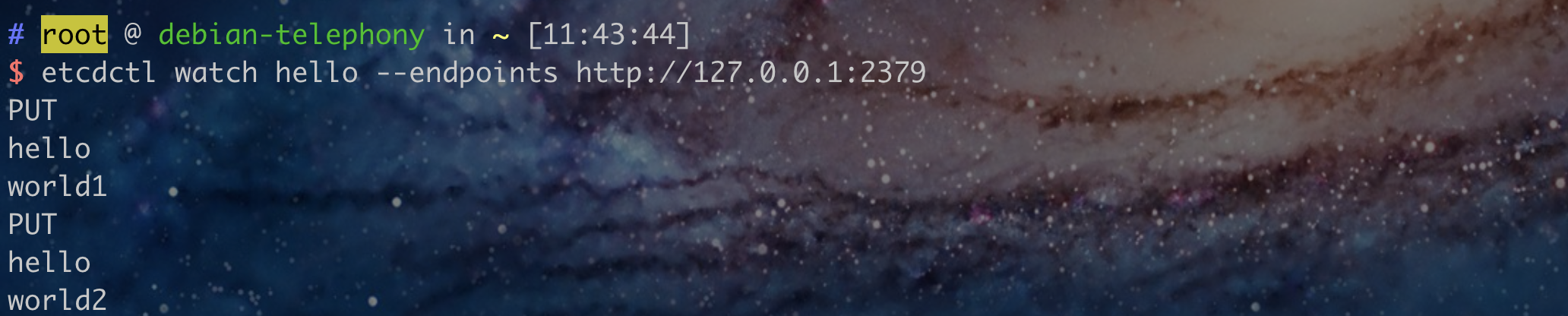
etcd watch
$ etcdctl watch hello --endpoints http://127.0.0.1:2379
$ etcdctl put hello world1 --endpoints http://127.0.0.1:2379
$ etcdctl put hello world2 --endpoints http://127.0.0.1:2379
etcd delete
$ etcdctl del hello --endpoints http://127.0.0.1:2379

etcd的核心原理概述
分布式共识算法:raft raft是etcd在分布式高可用和强一致性上的理论基础,是目前学术界和工业界在分布式共识领域中最易于理解和实现的算法。raft保障了etcd集群的稳定性,即使出现少数节点宕机等灾难事故也不影响整体的可用性!
存储引擎:B-Tree,boltdb B树是排序多叉树数据结构,拥有高效的构建、查询和检索效率。boltdb则是一个go语言的开源KV数据库,支持事务和持久化等能力。它们构成了etcd的底层核心存储引擎。
RPC框架和网络传输:gRPC gRPC是Google开源的基于HTTP/2.0的RPC框架,充分发挥了HTTP/2.0多路复用、流模式等特性,同时序列化基于protobuf相比于JSON更加高效。
参考
总结
本文简要介绍了etcd的历史诞生背景和发展史,阐述了etcd在Kubernetes中的核心作用。同时,本文还带领读者快速体验了etcd的主要API功能,并对其中的核心原理进行了概述。
etcd为我们在存储架构选型上提供了新的选择和思路,但使用它的同时也需要读者深入理解其核心原理,从而避免踩坑。