![]()
map不仅是Go语言的核心数据结构之一,更是整个编程世界最常见的核心数据结构之一。map描述了一种键与值的映射关系,开发者通常会通过键来查询其对应的值。map最常见的底层实现有两种:基于Hash散列和基于平衡树,两者的存取时间复杂度不同,Go语言的map属于前者范畴。
版本说明
本文涉及到的源码解析部分来源于go官方的1.16.5版本,其中英文部分的注释也属于源码,中文部分的注释则属于笔者添加。
Hash
Go语言map的底层实现基于Hash散列。Hash散列是一种著名的广义上的算法,它能够将任意长度的数据映射到有限的值域上面。
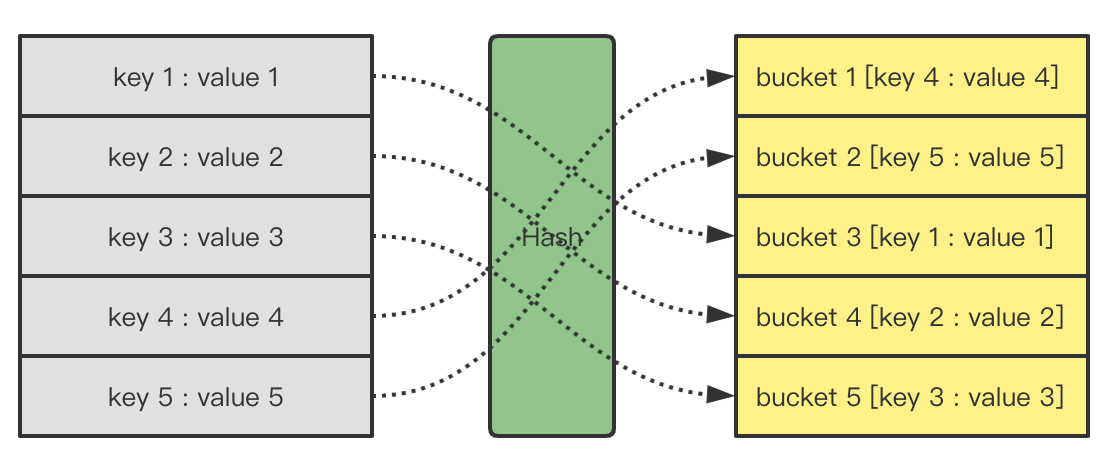
Hash算法有两大核心:设计Hash函数和解决Hash冲突。
设计Hash函数
设计Hash函数的基本原则有:
- 尽可能让输入的数据映射到不同的值域上面。
- 函数计算过程需要保证高性能。
但实际工程中由于输入数据范围是无限的,而输出值域范围是有限的,因此必然存在不同的输入数据经过映射后得到相同的输出值,这种现象称为Hash冲突。
以Java语言的String类型为例,让我们看一下它的默认hashCode()方法:
// s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Java选取31作为Magic Number,31不仅是奇数更是质数。stackoverflow上也有关于该问题的讨论:
- 从字典中选取超过50000个单词所计算出的Hash冲突数量小于7个,证明该函数有优秀的散列能力。
- 函数中的
31 * i == (i << 5) - i可以将乘法转化移位和减法,更适合计算机底层运算,证明该函数有优秀的计算耗时。
此外,常见的著名Hash算法还有:MD5、SHA1、SHA2等等。
解决Hash冲突
如何解决Hash冲突是Hash算法中的核心一环,最常见的做法是拉链法。所谓拉链法是指当Hash冲突产生时,将出现冲突的Bucket位用链表这一数据结构串联。
此外,在Java语言JDK 1.8中,HashMap的链表还引入了平衡树来优化局部链表过长的性能问题1。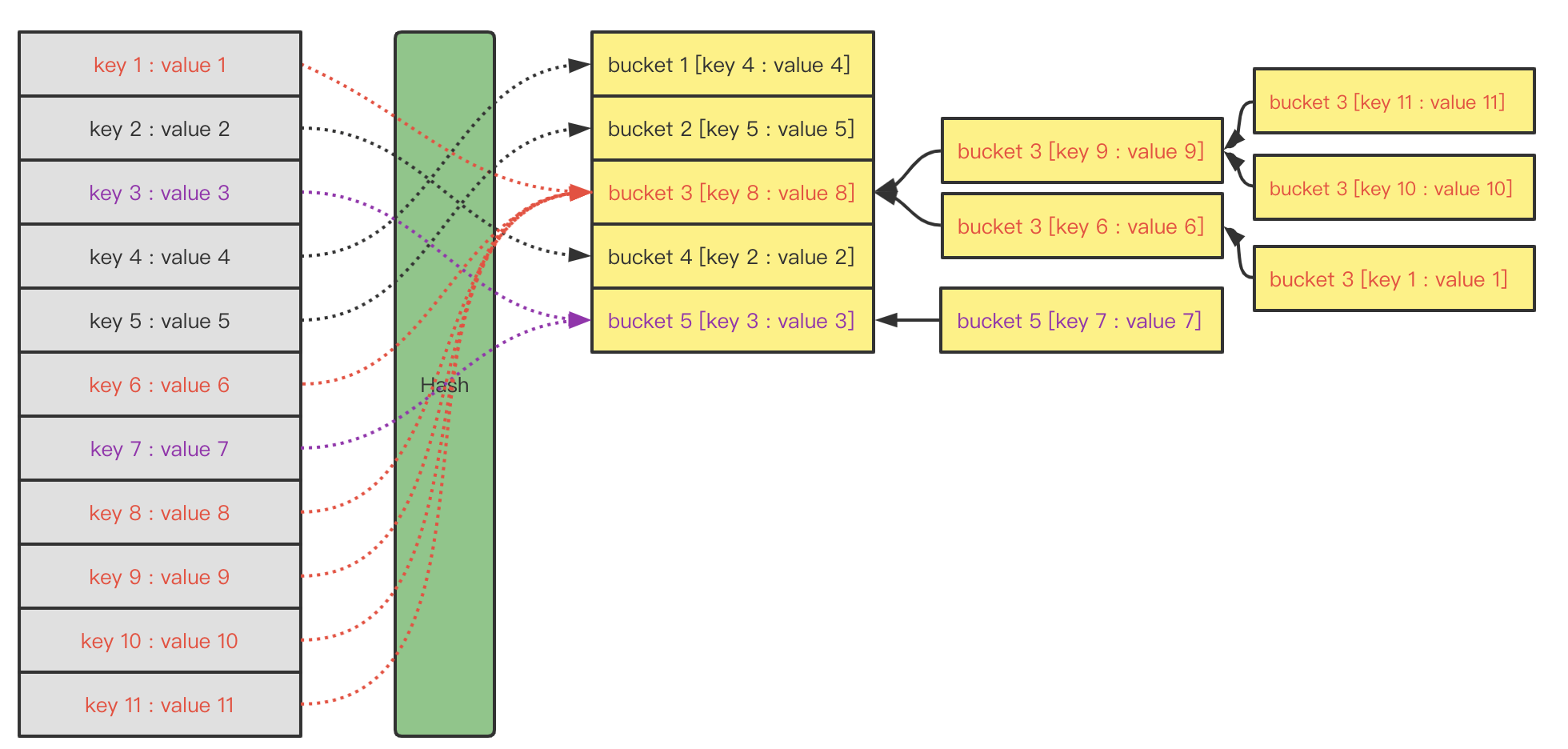
时间复杂度
Hash散列之所以成为map底层实现的首选,核心原因就是:平均增删改查时间复杂度都是O(1)。相比之下,基于平衡树的map(例如:C++ STL的map)平均时间复杂度是O(logN)。
| Algorithm | Action | Average Time Complexity | Worst Time Complexity |
|---|---|---|---|
| Hash | Insert | O(1) | O(N) |
| Hash | Delete | O(1) | O(N) |
| Hash | Update | O(1) | O(N) |
| Hash | Get | O(1) | O(N) |
| Balanced Binary Tree | Insert | O(logN) | O(logN) |
| Balanced Binary Tree | Delete | O(logN) | O(logN) |
| Balanced Binary Tree | Update | O(logN) | O(logN) |
| Balanced Binary Tree | Get | O(logN) | O(logN) |
需要注意的是,基于平衡树的map在最坏情况下依然能够保证时间复杂度是O(logN),并且能够提供key的有序遍历,这是基于Hash的map所不具备的能力。
map的定义
接下来让我们从源码角度详细解析Go语言的map实现。map是Go语言的内置数据类型之一,以map关键字作为Go语言的语法之一。runtime层的定义如下:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
map结构体各字段含义如下:
count:记录map当前存储的key数量,可以通过builtin包中的len()函数返回map的长度。flags:迭代map或者对map进行写操作的时候,会记录该标志位,用于一些并发场景的检测校验。B:存放当前map存放的bucket数组长度的对数,即len(buckets) == 2^B。noverflow:overflow的bucket近似数量。hash0:能够为Hash函数的结果引入随机性。buckets:指向具体的buckets数组。oldbuckets:当map扩容时候,指向旧的buckets数组。nevacuate:用于表示扩容的搬迁进度。extra:当map的key和value都不是指针,Go为了避免GC扫描整个hmap,会将bmap的overflow字段移动到extra。
上述hmap结构体中所提及的buckets即bmap的数组,bmap在Go语言runtime的源码如下:
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
不过在实际编译期间,Go语言的bmap会经过反射生成真正的bmap类型:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
bmap可存放最多8个kv,并且为了空间利用率,key和value分别存放,超过桶大小的部分会创建新的桶并通过overflow串联起来。顶层的tophash则存放了每个key Hash值的前8位,用于插入时候的快速比较等场景。
综上所述,map的整体结构大致如下: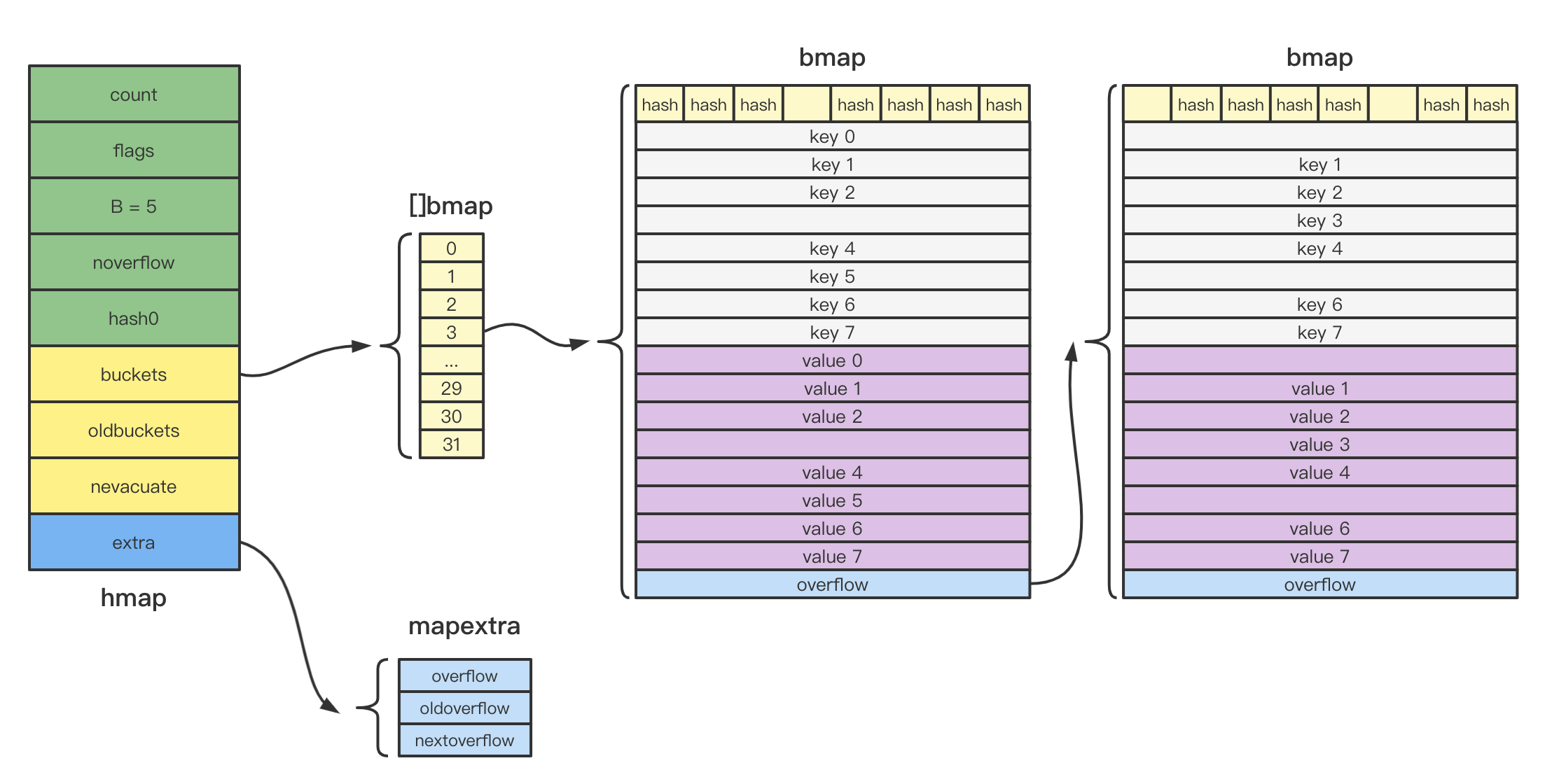
map的创建
基本用法
我们可以通过make函数创建并初始化map:
package main
import "fmt"
func main() {
m1 := make(map[int]int)
m2 := make(map[int]int, 10) // 创建map支持传递一个参数,表示初始大小
fmt.Println(m1, m2)
}
让我们通过go的官方工具来查看汇编结果:
$ go tool compile -S main.go
"".main STEXT size=207 args=0x0 locals=0x70 funcid=0x0
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $112-0
0x0000 00000 (main.go:5) MOVQ (TLS), CX
0x0009 00009 (main.go:5) CMPQ SP, 16(CX)
0x000d 00013 (main.go:5) PCDATA $0, $-2
0x000d 00013 (main.go:5) JLS 197
0x0013 00019 (main.go:5) PCDATA $0, $-1
0x0013 00019 (main.go:5) SUBQ $112, SP
0x0017 00023 (main.go:5) MOVQ BP, 104(SP)
0x001c 00028 (main.go:5) LEAQ 104(SP), BP
0x0021 00033 (main.go:5) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x0021 00033 (main.go:5) FUNCDATA $1, gclocals·d527b79a98f329c2ba624a68e7df03d6(SB)
0x0021 00033 (main.go:5) FUNCDATA $2, "".main.stkobj(SB)
0x0021 00033 (main.go:6) PCDATA $1, $0
0x0021 00033 (main.go:6) CALL runtime.makemap_small(SB)
0x0026 00038 (main.go:6) MOVQ (SP), AX
0x002a 00042 (main.go:6) MOVQ AX, ""..autotmp_25+64(SP)
0x002f 00047 (main.go:7) LEAQ type.map[int]int(SB), CX
0x0036 00054 (main.go:7) MOVQ CX, (SP)
0x003a 00058 (main.go:7) MOVQ $10, 8(SP)
0x0043 00067 (main.go:7) MOVQ $0, 16(SP)
0x004c 00076 (main.go:7) PCDATA $1, $1
0x004c 00076 (main.go:7) CALL runtime.makemap(SB)
0x0051 00081 (main.go:7) MOVQ 24(SP), AX
0x0056 00086 (main.go:9) XORPS X0, X0
0x0059 00089 (main.go:9) MOVUPS X0, ""..autotmp_17+72(SP)
0x005e 00094 (main.go:9) MOVUPS X0, ""..autotmp_17+88(SP)
0x0063 00099 (main.go:9) LEAQ type.map[int]int(SB), CX
0x006a 00106 (main.go:9) MOVQ CX, ""..autotmp_17+72(SP)
0x006f 00111 (main.go:9) MOVQ ""..autotmp_25+64(SP), DX
0x0074 00116 (main.go:9) MOVQ DX, ""..autotmp_17+80(SP)
0x0079 00121 (main.go:9) MOVQ CX, ""..autotmp_17+88(SP)
0x007e 00126 (main.go:9) MOVQ AX, ""..autotmp_17+96(SP)
... 省略不相关的部分
从汇编结果中,我们可以看出make对应的底层实现出现了两种不同的结果:runtime.makemap_small和runtime.makemap。让我们进一步翻阅相关的源码:
// makemap_small implements Go map creation for make(map[k]v) and
// make(map[k]v, hint) when hint is known to be at most bucketCnt
// at compile time and the map needs to be allocated on the heap.
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
从以上源码中,我们可以得出一个结论:当编译期能够确定map的长度不大于bucketCnt(也就是8),将会对应到底层的runtime.makemap_small实现。makemap_small只是简单创建了hmap的结构体并没有初始化buckets。
其它情况最终都会调用runtime.makemap(笔者已在关键位置加上中文注释):
// makemap implements Go map creation for make(map[k]v, hint).
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
// 如果编译器发现map或者它第一个bucket能够被分配在栈上,则传入的h参数将不为空。
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
// hint表示创建map的预期初始大小,因此要计算一个合适的对数B
// overLoadFactor即用于判断当前的2^B是否已经超过hint
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
// 如果B == 0,则Buckets数组将会延迟初始化,直到调用mapassign给该map存值
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) // 给Buckets数组分配内存
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
此外,从Go的源码中也发现另外一个runtime.makemap64函数,这是当传入的初始长度类型为int64时候会调用:
func makemap64(t *maptype, hint int64, h *hmap) *hmap {
if int64(int(hint)) != hint {
hint = 0
}
return makemap(t, int(hint), h)
}
小结一下,map的创建底层有三种实现:
makemap_small:当map编译期确定初始长度不大于8,只创建hmap,不初始化buckets。makemap64:当make函数传递的长度参数类型是int64时候,调用该函数,底层仍然是复用makemap。makemap:初始化hash0加入随机性,计算对数B,并初始化buckets。
选择Hash函数
map底层使用的Hash函数在runtime层的初始化中会根据CPU架构和一些系统支持来选择。让我们翻阅相关源码:
func alginit() {
// Install AES hash algorithms if the instructions needed are present.
// 对于386/amd64/arm64都优先判断是否支持AES Hash函数
if (GOARCH == "386" || GOARCH == "amd64") &&
cpu.X86.HasAES && // AESENC
cpu.X86.HasSSSE3 && // PSHUFB
cpu.X86.HasSSE41 { // PINSR{D,Q}
initAlgAES()
return
}
if GOARCH == "arm64" && cpu.ARM64.HasAES {
initAlgAES()
return
}
getRandomData((*[len(hashkey) * sys.PtrSize]byte)(unsafe.Pointer(&hashkey))[:])
hashkey[0] |= 1 // make sure these numbers are odd
hashkey[1] |= 1
hashkey[2] |= 1
hashkey[3] |= 1
}
由上述源码可知,map的Hash函数优先选择AES,不支持的情况下进入默认逻辑。
map的访问
概述
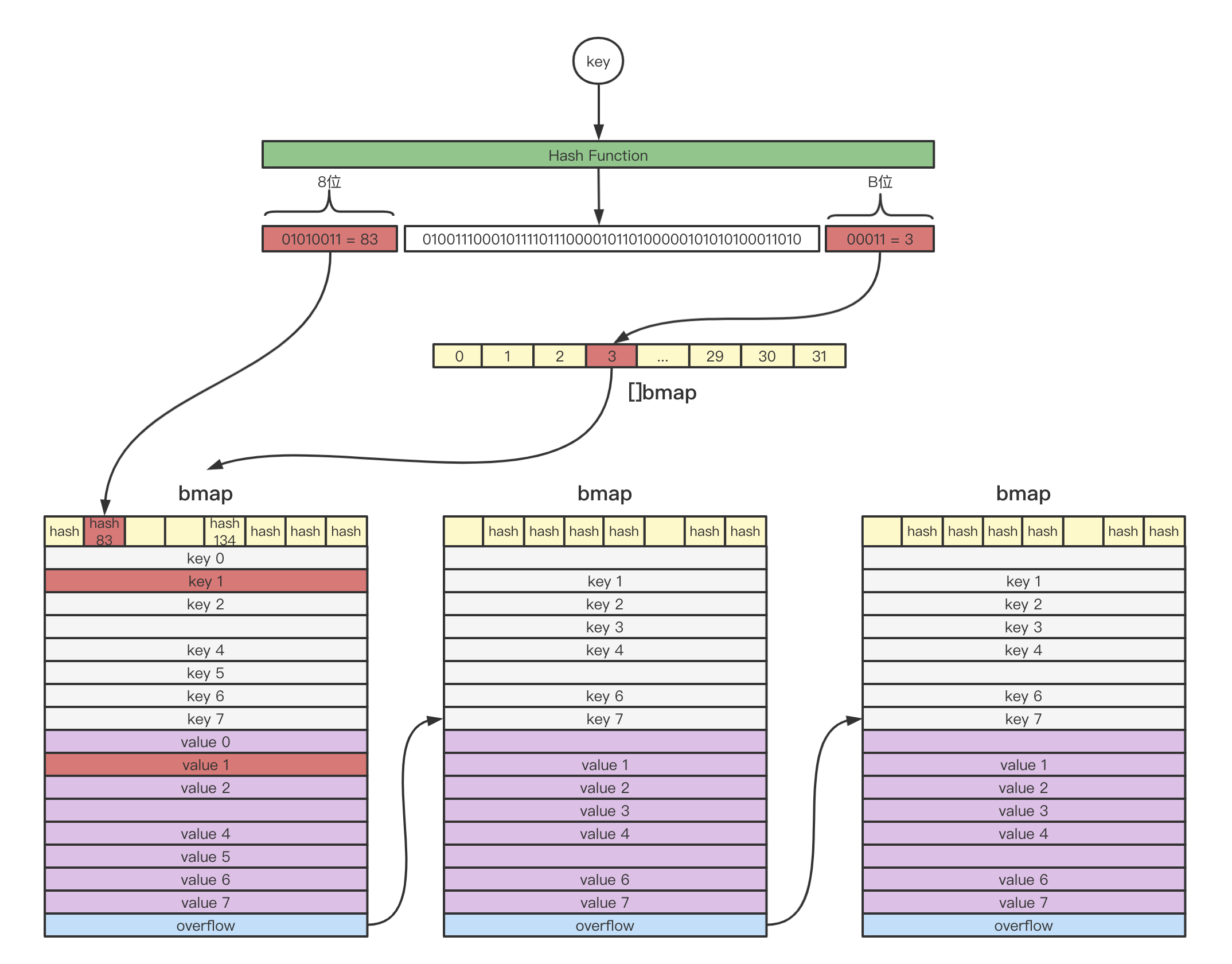
map的访问即通过给定的key在map中寻找其对应value,它的大致步骤如下:
- 以64位操作系统为例,原始的key通过Hash函数映射成64位二进制。
- 末尾B位对应
bmap的位置,从[]bmap中找到对应的bmap。 - 首8位对应该key的
tophash,从步骤2所定位的bmap开始检索。首先会比较bmap顶层的tophash与原始key的tophash是否相同,若不相同则直接跳过比较下一个;若相同则进一步比较key是否相同。 - 若当前的
bmap中比较完,没有匹配到目标key,且overflow不为空,则继续从overflow指向的下一个bmap继续比较。
基本用法
map的访问方式直接通过key下标获取,返回值可以是一个value,也可以在此基础上多一个表示是否存在的bool:
package main
import "fmt"
func main() {
m := map[int8]int{
1: 1,
2: 2,
3: 3,
}
v1 := m[1]
v2, ok := m[2] // ok是一个bool值,用于判断是否存在2这个key
fmt.Println(v1)
fmt.Println(v2, ok)
}
让我们通过go的官方工具来查看汇编结果:
$ go tool compile -S main.go
"".main STEXT size=741 args=0x0 locals=0x120 funcid=0x0
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $288-0
0x0000 00000 (main.go:5) MOVQ (TLS), CX
0x0009 00009 (main.go:5) LEAQ -160(SP), AX
0x0011 00017 (main.go:5) CMPQ AX, 16(CX)
0x0015 00021 (main.go:5) PCDATA $0, $-2
0x0015 00021 (main.go:5) JLS 726
0x001b 00027 (main.go:5) PCDATA $0, $-1
0x001b 00027 (main.go:5) SUBQ $288, SP
0x0022 00034 (main.go:5) MOVQ BP, 280(SP)
0x002a 00042 (main.go:5) LEAQ 280(SP), BP
0x0032 00050 (main.go:5) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x0032 00050 (main.go:5) FUNCDATA $1, gclocals·164458436596f10dcbb268ec85fd5e10(SB)
0x0032 00050 (main.go:5) FUNCDATA $2, "".main.stkobj(SB)
0x0032 00050 (main.go:6) XORPS X0, X0
0x0035 00053 (main.go:6) MOVUPS X0, ""..autotmp_20+232(SP)
0x003d 00061 (main.go:6) MOVUPS X0, ""..autotmp_20+248(SP)
0x0045 00069 (main.go:6) MOVUPS X0, ""..autotmp_20+264(SP)
0x004d 00077 (main.go:6) MOVQ $0, ""..autotmp_21+96(SP)
0x0056 00086 (main.go:6) LEAQ ""..autotmp_21+104(SP), DI
0x005b 00091 (main.go:6) PCDATA $0, $-2
0x005b 00091 (main.go:6) LEAQ -48(DI), DI
0x005f 00095 (main.go:6) NOP
0x0060 00096 (main.go:6) DUFFZERO $277
0x0073 00115 (main.go:6) PCDATA $0, $-1
0x0073 00115 (main.go:6) LEAQ ""..autotmp_21+96(SP), AX
0x0078 00120 (main.go:6) MOVQ AX, ""..autotmp_20+248(SP)
0x0080 00128 (main.go:6) PCDATA $1, $1
0x0080 00128 (main.go:6) CALL runtime.fastrand(SB)
0x0085 00133 (main.go:6) MOVL (SP), AX
0x0088 00136 (main.go:6) MOVL AX, ""..autotmp_20+244(SP)
0x008f 00143 (main.go:7) MOVB $1, ""..autotmp_24+71(SP)
0x0094 00148 (main.go:7) LEAQ type.map[int8]int(SB), AX
0x009b 00155 (main.go:7) MOVQ AX, (SP)
0x009f 00159 (main.go:7) LEAQ ""..autotmp_20+232(SP), CX
0x00a7 00167 (main.go:7) MOVQ CX, 8(SP)
0x00ac 00172 (main.go:7) LEAQ ""..autotmp_24+71(SP), DX
0x00b1 00177 (main.go:7) MOVQ DX, 16(SP)
0x00b6 00182 (main.go:7) CALL runtime.mapassign(SB)
0x00bb 00187 (main.go:7) MOVQ 24(SP), AX
0x00c0 00192 (main.go:7) MOVQ $1, (AX)
0x00c7 00199 (main.go:8) MOVB $2, ""..autotmp_24+71(SP)
0x00cc 00204 (main.go:8) LEAQ type.map[int8]int(SB), AX
0x00d3 00211 (main.go:8) MOVQ AX, (SP)
0x00d7 00215 (main.go:8) LEAQ ""..autotmp_20+232(SP), CX
0x00df 00223 (main.go:8) MOVQ CX, 8(SP)
0x00e4 00228 (main.go:8) LEAQ ""..autotmp_24+71(SP), DX
0x00e9 00233 (main.go:8) MOVQ DX, 16(SP)
0x00ee 00238 (main.go:8) CALL runtime.mapassign(SB)
0x00f3 00243 (main.go:8) MOVQ 24(SP), AX
0x00f8 00248 (main.go:8) MOVQ $2, (AX)
0x00ff 00255 (main.go:9) MOVB $3, ""..autotmp_24+71(SP)
0x0104 00260 (main.go:9) LEAQ type.map[int8]int(SB), AX
0x010b 00267 (main.go:9) MOVQ AX, (SP)
0x010f 00271 (main.go:9) LEAQ ""..autotmp_20+232(SP), CX
0x0117 00279 (main.go:9) MOVQ CX, 8(SP)
0x011c 00284 (main.go:9) LEAQ ""..autotmp_24+71(SP), DX
0x0121 00289 (main.go:9) MOVQ DX, 16(SP)
0x0126 00294 (main.go:9) CALL runtime.mapassign(SB)
0x012b 00299 (main.go:9) MOVQ 24(SP), AX
0x0130 00304 (main.go:9) MOVQ $3, (AX)
0x0137 00311 (main.go:12) LEAQ type.map[int8]int(SB), AX
0x013e 00318 (main.go:12) MOVQ AX, (SP)
0x0142 00322 (main.go:12) LEAQ ""..autotmp_20+232(SP), CX
0x014a 00330 (main.go:12) MOVQ CX, 8(SP)
0x014f 00335 (main.go:12) LEAQ ""..stmp_0(SB), DX
0x0156 00342 (main.go:12) MOVQ DX, 16(SP)
0x015b 00347 (main.go:12) NOP
0x0160 00352 (main.go:12) CALL runtime.mapaccess1(SB)
0x0165 00357 (main.go:12) MOVQ 24(SP), AX
0x016a 00362 (main.go:12) MOVQ (AX), AX
0x016d 00365 (main.go:12) MOVQ AX, "".v1+80(SP)
0x0172 00370 (main.go:13) LEAQ type.map[int8]int(SB), CX
0x0179 00377 (main.go:13) MOVQ CX, (SP)
0x017d 00381 (main.go:13) LEAQ ""..autotmp_20+232(SP), CX
0x0185 00389 (main.go:13) MOVQ CX, 8(SP)
0x018a 00394 (main.go:13) LEAQ ""..stmp_1(SB), CX
0x0191 00401 (main.go:13) MOVQ CX, 16(SP)
0x0196 00406 (main.go:13) PCDATA $1, $0
0x0196 00406 (main.go:13) CALL runtime.mapaccess2(SB)
0x019b 00411 (main.go:13) MOVQ 24(SP), AX
0x01a0 00416 (main.go:13) MOVQ (AX), AX
0x01a3 00419 (main.go:13) MOVQ AX, "".v2+72(SP)
0x01a8 00424 (main.go:13) MOVBLZX 32(SP), CX
0x01ad 00429 (main.go:13) MOVQ CX, ""..autotmp_53+88(SP)
0x01b2 00434 (main.go:15) MOVQ "".v1+80(SP), DX
0x01b7 00439 (main.go:15) MOVQ DX, (SP)
0x01bb 00443 (main.go:15) NOP
0x01c0 00448 (main.go:15) CALL runtime.convT64(SB)
0x01c5 00453 (main.go:15) MOVQ 8(SP), AX
0x01ca 00458 (main.go:15) XORPS X1, X1
0x01cd 00461 (main.go:15) MOVUPS X1, ""..autotmp_34+184(SP)
0x01d5 00469 (main.go:15) LEAQ type.int(SB), CX
0x01dc 00476 (main.go:15) MOVQ CX, ""..autotmp_34+184(SP)
0x01e4 00484 (main.go:15) MOVQ AX, ""..autotmp_34+192(SP)
... 省略不相关的部分
从汇编的结果中,我们可以看出map的访问对应到底层主要是runtime.mapaccess1和runtime.mapaccess2两个方法:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
其中mapaccess2相比mapaccess1多出一个bool的返回值,表示该key是否存在,其它逻辑基本一致。接下来主要分析mapaccess1的实现:
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
// it will return a reference to the zero object for the elem type if
// the key is not in the map.
// NOTE: The returned pointer may keep the whole map live, so don't
// hold onto it for very long.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// map不允许并发读写,会触发该panic。这里是通过flags的标记位来判断是否正在进行写操作。
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B) // m即后B位,用于定位[]bmap中对应的bmap。
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) // 定位到具体的bmap。
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash) // tophash即首8位,用于快速比较。
bucketloop:
// 遍历迭代bmap和它的overflow bmap。
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 首先比较tophash是否相同,不相同会直接continue。
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// tophash相同的情况下,会比较key的值是否相同。若相同,则说明已经定位到该key,返回结果。
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
key是string/32位整型/64位整型
值得一提的是,当map对应的key类型是string、int32/uint32、int64/uint64其中之一的时候,在Go语言runtime中将会被汇编成不同的函数。下面列出函数签名:
func mapaccess1_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
func mapaccess2_fast32(t *maptype, h *hmap, key uint32) (unsafe.Pointer, bool)
func mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer
func mapaccess2_fast64(t *maptype, h *hmap, key uint64) (unsafe.Pointer, bool)
func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer
func mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool)
整体逻辑与mapaccess1和mapaccess2框架一致,Go语言针对这几种确定类型会有一定的逻辑优化。以int64为例(直接比较key):
func mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapaccess1_fast64))
}
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
var b *bmap
if h.B == 0 {
// One-bucket table. No need to hash.
b = (*bmap)(h.buckets)
} else {
hash := t.hasher(noescape(unsafe.Pointer(&key)), uintptr(h.hash0))
m := bucketMask(h.B)
b = (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
}
for ; b != nil; b = b.overflow(t) {
for i, k := uintptr(0), b.keys(); i < bucketCnt; i, k = i+1, add(k, 8) {
if *(*uint64)(k) == key && !isEmpty(b.tophash[i]) { // 直接比较key,没有先比较tophash再比较key。
return add(unsafe.Pointer(b), dataOffset+bucketCnt*8+i*uintptr(t.elemsize))
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
map的赋值
概述
不考虑扩容的情况下,map的赋值与map的访问基本逻辑是一致的。首先遵循map访问的方式通过后B位定位bmap,通过前8位快速比较tophash。当map中不存在这个key,会记录bmap中的第一个空闲的tophash,并插入该key。当map中存在这个key,会更新该key的value。
基本用法
package main
import "fmt"
func main() {
m := make(map[int8]int)
m[1] = 1
fmt.Println(m)
}
让我们通过go的官方工具来查看汇编结果:
$ go tool compile -S main.go
"".main STEXT size=202 args=0x0 locals=0x60 funcid=0x0
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $96-0
0x0000 00000 (main.go:5) MOVQ (TLS), CX
0x0009 00009 (main.go:5) CMPQ SP, 16(CX)
0x000d 00013 (main.go:5) PCDATA $0, $-2
0x000d 00013 (main.go:5) JLS 192
0x0013 00019 (main.go:5) PCDATA $0, $-1
0x0013 00019 (main.go:5) SUBQ $96, SP
0x0017 00023 (main.go:5) MOVQ BP, 88(SP)
0x001c 00028 (main.go:5) LEAQ 88(SP), BP
0x0021 00033 (main.go:5) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x0021 00033 (main.go:5) FUNCDATA $1, gclocals·713abd6cdf5e052e4dcd3eb297c82601(SB)
0x0021 00033 (main.go:5) FUNCDATA $2, "".main.stkobj(SB)
0x0021 00033 (main.go:6) PCDATA $1, $0
0x0021 00033 (main.go:6) CALL runtime.makemap_small(SB)
0x0026 00038 (main.go:6) MOVQ (SP), AX
0x002a 00042 (main.go:6) MOVQ AX, ""..autotmp_20+64(SP)
0x002f 00047 (main.go:8) LEAQ type.map[int8]int(SB), CX
0x0036 00054 (main.go:8) MOVQ CX, (SP)
0x003a 00058 (main.go:8) MOVQ AX, 8(SP)
0x003f 00063 (main.go:8) LEAQ ""..stmp_0(SB), DX
0x0046 00070 (main.go:8) MOVQ DX, 16(SP)
0x004b 00075 (main.go:8) PCDATA $1, $1
0x004b 00075 (main.go:8) CALL runtime.mapassign(SB)
0x0050 00080 (main.go:8) MOVQ 24(SP), AX
0x0055 00085 (main.go:8) MOVQ $1, (AX)
0x005c 00092 (main.go:10) XORPS X0, X0
0x005f 00095 (main.go:10) MOVUPS X0, ""..autotmp_14+72(SP)
0x0064 00100 (main.go:10) LEAQ type.map[int8]int(SB), AX
0x006b 00107 (main.go:10) MOVQ AX, ""..autotmp_14+72(SP)
0x0070 00112 (main.go:10) MOVQ ""..autotmp_20+64(SP), AX
0x0075 00117 (main.go:10) MOVQ AX, ""..autotmp_14+80(SP)
... 省略不相关的部分
从汇编结果中,我们可以看出map的赋值对应的底层实现主要是runtime.mapassign:
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled {
msanread(key, t.key.size)
}
// map不允许并发读写,通过flags的位判断。
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
// 因为赋值是写操作,因此置位flags写标志。
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() { // 判断是否处于扩容中。
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) // 定位bmap
top := tophash(hash) // 计算tophash
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 当遇到第一个空闲位置的tophash,记录下来。
// 遍历完整个bmap及其overflow bmap,没有找到该key,则认为map中不存在该key。
// 最终插入位置即这里记录的位置。
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
// 表明在map中已经存在这个key,那么就需要对该key的值进行更新操作。
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t) // 继续遍历下一个overflow bmap
if ovf == nil {
break
}
b = ovf
}
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
// 触发扩容的情况。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// The current bucket and all the overflow buckets connected to it are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting // 将写操作标记位置空。
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
key是string/32位整型/64位整型
与map的访问同理,当map对应的key类型是string、int32/uint32、int64/uint64其中之一,Go语言的runtime层会调用不同函数,签名如下:
func mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer
map的扩容
概述
map扩容的目的在于减少Hash冲突,防止算法复杂度退化,保持Hash算法O(1)的时间复杂度。
map的扩容对使用方不可见,开发者在使用map的过程中是不会感知到map是否处于扩容中,以及当前扩容的进度。Go语言的map扩容是渐进式的,即整个扩容过程拆散在每一次的写操作里面,这样做的好处是保证每一次map的读写操作时间复杂度都是稳定的。
map触发扩容的时机有两个:
map的负载因子(长度与容量的比例)超过阈值,此时map被认为无法承担更多的key,需要进行2倍扩容。
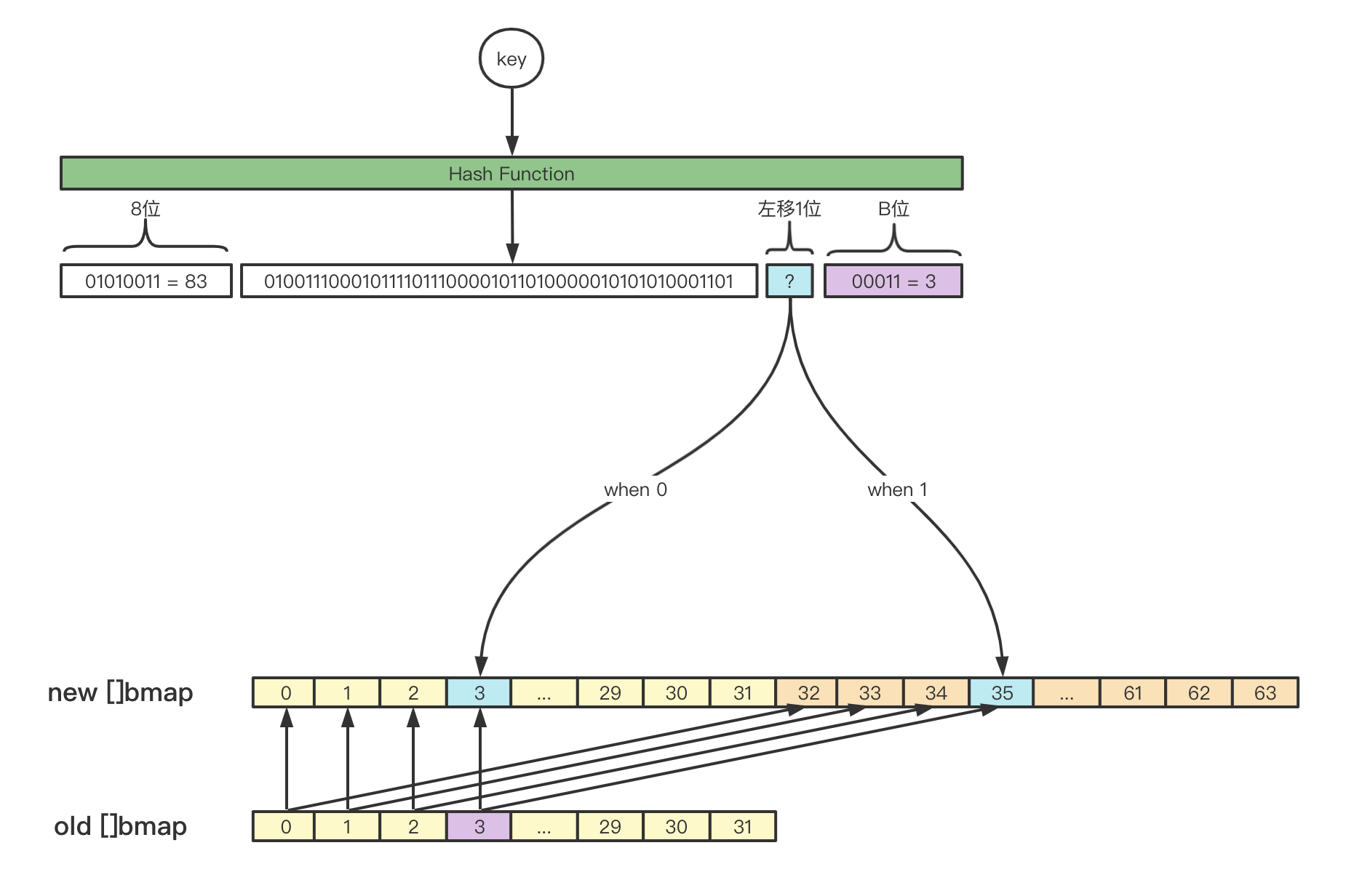
负载因子超过阈值 map存在局部bmap包含过多overflow的情况,此时map会认为局部的bmap可以进行tophash密集排列,让overflow数量更少。
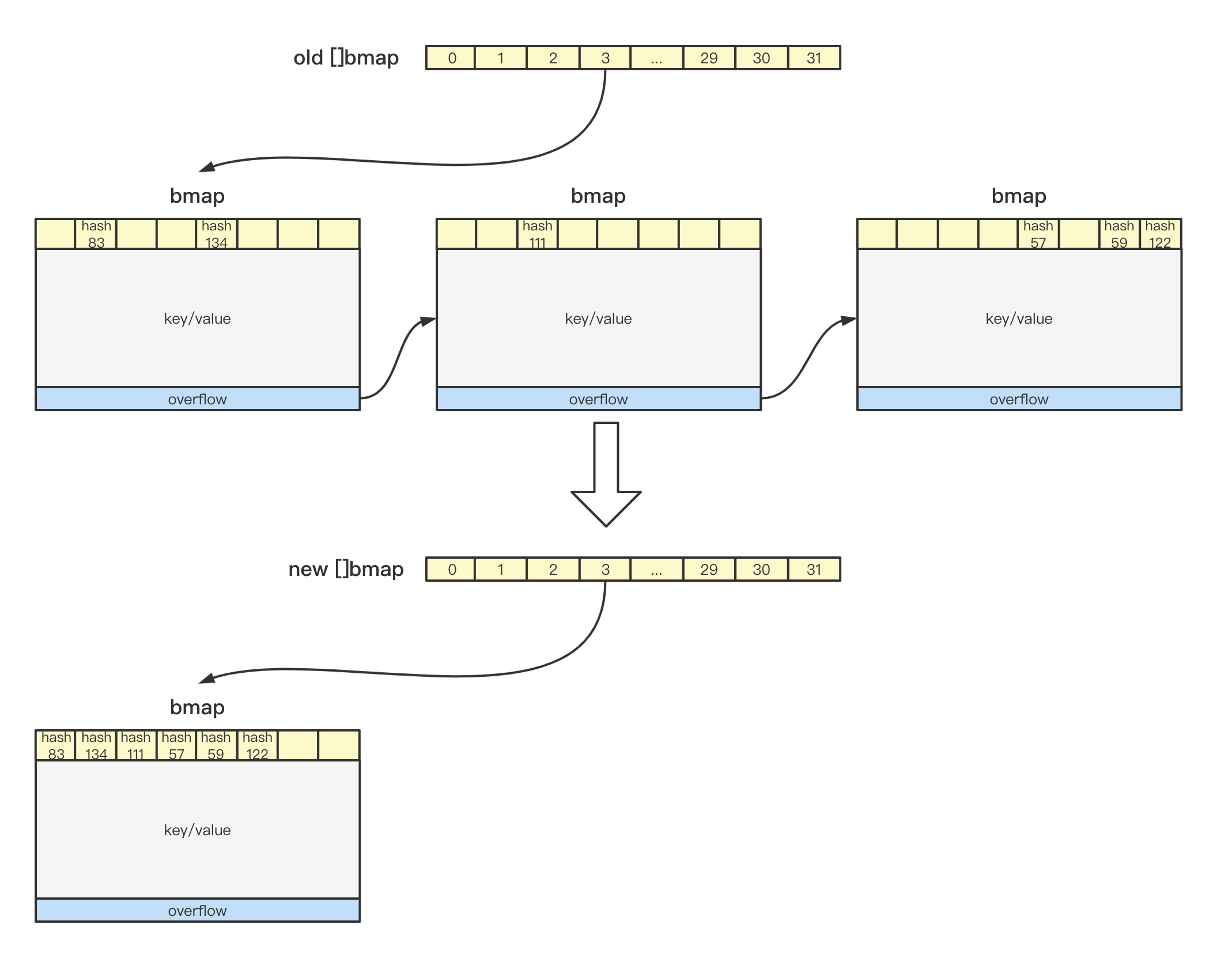
局部overflow过多
扩容过程
首先,我们通过源码来查看如何判断负载因子是否超过阈值:
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// bucketShift returns 1<<b, optimized for code generation.
func bucketShift(b uint8) uintptr {
// Masking the shift amount allows overflow checks to be elided.
return uintptr(1) << (b & (sys.PtrSize*8 - 1))
}
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
)
从上述源码逻辑可以看出,loadFactorNum和loadFactorDen是预定义的负载因子阈值,所以负载因子阈值是6.5。而实际的负载因子由count和bucketShift(B)决定,也就是长度/桶个数。
接下来分析一下hashGrow:
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) { // 如果不是负载因子超过阈值,那么本次map的扩容实际上更应该理解为map的整理,容量不变。
bigger = 0
h.flags |= sameSizeGrow // 标记sameSizeGrow,表示容量不变。
}
oldbuckets := h.buckets // 保留旧的buckets。
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) // 创建新的buckets。
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0 // 表示搬迁进度,从0开始将会依次递增,每调用一次evacuate()会自增一次。
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
由此可见,真正执行map扩容过程的逻辑在evacuate中:
// evacDst is an evacuation destination.
type evacDst struct {
b *bmap // current destination bucket // 搬迁目标bmap。
i int // key/elem index into b // 目标bmap的当前索引。
k unsafe.Pointer // pointer to current key storage // 当前key。
e unsafe.Pointer // pointer to current elem storage // 当前value。
}
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) // 定位旧bmap。
newbit := h.noldbuckets()
if !evacuated(b) { // 判断是否已经被搬迁过。
// TODO: reuse overflow buckets instead of using new ones, if there
// is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() { // 对于2倍扩容的场景,搬迁目标可能有2个,因此xy[1]记录另一个目标。
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
for ; b != nil; b = b.overflow(t) { // 遍历当前的bmap。
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() { // 对于2倍扩容的场景,要重新计算tophash
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// If key != key (NaNs), then the hash could be (and probably
// will be) entirely different from the old hash. Moreover,
// it isn't reproducible. Reproducibility is required in the
// presence of iterators, as our evacuation decision must
// match whatever decision the iterator made.
// Fortunately, we have the freedom to send these keys either
// way. Also, tophash is meaningless for these kinds of keys.
// We let the low bit of tophash drive the evacuation decision.
// We recompute a new random tophash for the next level so
// these keys will get evenly distributed across all buckets
// after multiple grows.
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 拷贝内存数据到新的搬迁位置
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// Unlink the overflow buckets & clear key/elem to help GC.
// 把旧的bmap引用解除,便于GC完成内存回收。
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
map的删除
概述
map的删除与map的访问基本逻辑也是一致的。遍历bmap与overflow寻找目标key,如果找到则清空tophash并删除key/value释放内存。
基本用法
删除map中的元素可以通过builtin中的delete函数完成:
package main
func main() {
m := make(map[int8]int)
delete(m, 1)
}
让我们通过go的官方工具来查看汇编结果:
$ go tool compile -S main.go
"".main STEXT size=204 args=0x0 locals=0xa8 funcid=0x0
0x0000 00000 (main.go:3) TEXT "".main(SB), ABIInternal, $168-0
0x0000 00000 (main.go:3) MOVQ (TLS), CX
0x0009 00009 (main.go:3) LEAQ -40(SP), AX
0x000e 00014 (main.go:3) CMPQ AX, 16(CX)
0x0012 00018 (main.go:3) PCDATA $0, $-2
0x0012 00018 (main.go:3) JLS 194
0x0018 00024 (main.go:3) PCDATA $0, $-1
0x0018 00024 (main.go:3) SUBQ $168, SP
0x001f 00031 (main.go:3) MOVQ BP, 160(SP)
0x0027 00039 (main.go:3) LEAQ 160(SP), BP
0x002f 00047 (main.go:3) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x002f 00047 (main.go:3) FUNCDATA $1, gclocals·d9a525d1de6bc16975a5efbb873db17d(SB)
0x002f 00047 (main.go:3) FUNCDATA $2, "".main.stkobj(SB)
0x002f 00047 (main.go:4) XORPS X0, X0
0x0032 00050 (main.go:4) MOVUPS X0, ""..autotmp_1+112(SP)
0x0037 00055 (main.go:4) MOVUPS X0, ""..autotmp_1+128(SP)
0x003f 00063 (main.go:4) MOVUPS X0, ""..autotmp_1+144(SP)
0x0047 00071 (main.go:4) MOVQ $0, ""..autotmp_2+24(SP)
0x0050 00080 (main.go:4) LEAQ ""..autotmp_2+32(SP), DI
0x0055 00085 (main.go:4) PCDATA $0, $-2
0x0055 00085 (main.go:4) LEAQ -48(DI), DI
0x0059 00089 (main.go:4) NOP
0x0060 00096 (main.go:4) DUFFZERO $277
0x0073 00115 (main.go:4) PCDATA $0, $-1
0x0073 00115 (main.go:4) LEAQ ""..autotmp_2+24(SP), AX
0x0078 00120 (main.go:4) MOVQ AX, ""..autotmp_1+128(SP)
0x0080 00128 (main.go:4) PCDATA $1, $1
0x0080 00128 (main.go:4) CALL runtime.fastrand(SB)
0x0085 00133 (main.go:4) MOVL (SP), AX
0x0088 00136 (main.go:4) MOVL AX, ""..autotmp_1+124(SP)
0x008c 00140 (main.go:6) LEAQ type.map[int8]int(SB), AX
0x0093 00147 (main.go:6) MOVQ AX, (SP)
0x0097 00151 (main.go:6) LEAQ ""..autotmp_1+112(SP), AX
0x009c 00156 (main.go:6) MOVQ AX, 8(SP)
0x00a1 00161 (main.go:6) LEAQ ""..stmp_0(SB), AX
0x00a8 00168 (main.go:6) MOVQ AX, 16(SP)
0x00ad 00173 (main.go:6) PCDATA $1, $0
0x00ad 00173 (main.go:6) CALL runtime.mapdelete(SB)
0x00b2 00178 (main.go:7) MOVQ 160(SP), BP
0x00ba 00186 (main.go:7) ADDQ $168, SP
0x00c1 00193 (main.go:7) RET
0x00c2 00194 (main.go:7) NOP
0x00c2 00194 (main.go:3) PCDATA $1, $-1
0x00c2 00194 (main.go:3) PCDATA $0, $-2
0x00c2 00194 (main.go:3) CALL runtime.morestack_noctxt(SB)
0x00c7 00199 (main.go:3) PCDATA $0, $-1
0x00c7 00199 (main.go:3) JMP 0
... 省略不相关的部分
从编译结果中,我们可以看出map的删除底层实现是runtime.mapdelete:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapdelete)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write (delete).
h.flags ^= hashWriting
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.key.equal(key, k2) {
continue
}
// 删除key
// Only clear key if there are pointers in it.
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
// 删除value
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 清空tophash
b.tophash[i] = emptyOne
// If the bucket now ends in a bunch of emptyOne states,
// change those to emptyRest states.
// It would be nice to make this a separate function, but
// for loops are not currently inlineable.
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
h.count--
// Reset the hash seed to make it more difficult for attackers to
// repeatedly trigger hash collisions. See issue 25237.
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
key是string/32位整型/64位整型
与map的访问同理,当map对应的key类型是string、int32/uint32、int64/uint64其中之一,Go语言的runtime层会调用不同函数,签名如下:
func mapdelete_fast32(t *maptype, h *hmap, key uint32)
func mapdelete_fast64(t *maptype, h *hmap, key uint64)
func mapdelete_faststr(t *maptype, h *hmap, ky string)
map的迭代
概述
由于map存在渐进式扩容,因此map的迭代并不像想象中的那么直接,而需要考虑搬迁过程中的迭代。在上文的描述中,我们知道,map在搬迁过程中会通过nevacuate来记录搬迁进度,因此在迭代过程中需要同时考虑遍历旧的bmap和新的bmap。
基本用法
map的迭代通过Go语言的基本语法for range完成:
package main
import "fmt"
func main() {
m := make(map[int8]int)
for k, v := range m {
fmt.Println(k, v)
}
}
让我们通过go的官方工具来查看汇编结果:
$ go tool compile -S main.go
"".main STEXT size=466 args=0x0 locals=0x158 funcid=0x0
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $344-0
0x0000 00000 (main.go:5) MOVQ (TLS), CX
0x0009 00009 (main.go:5) LEAQ -216(SP), AX
0x0011 00017 (main.go:5) CMPQ AX, 16(CX)
0x0015 00021 (main.go:5) PCDATA $0, $-2
0x0015 00021 (main.go:5) JLS 456
0x001b 00027 (main.go:5) PCDATA $0, $-1
0x001b 00027 (main.go:5) SUBQ $344, SP
0x0022 00034 (main.go:5) MOVQ BP, 336(SP)
0x002a 00042 (main.go:5) LEAQ 336(SP), BP
0x0032 00050 (main.go:5) FUNCDATA $0, gclocals·7d2d5fca80364273fb07d5820a76fef4(SB)
0x0032 00050 (main.go:5) FUNCDATA $1, gclocals·78b4c479b253ac6bc6556563a2e18726(SB)
0x0032 00050 (main.go:5) FUNCDATA $2, "".main.stkobj(SB)
0x0032 00050 (main.go:6) XORPS X0, X0
0x0035 00053 (main.go:6) MOVUPS X0, ""..autotmp_15+192(SP)
0x003d 00061 (main.go:6) MOVUPS X0, ""..autotmp_15+208(SP)
0x0045 00069 (main.go:6) MOVUPS X0, ""..autotmp_15+224(SP)
0x004d 00077 (main.go:6) MOVQ $0, ""..autotmp_16+72(SP)
0x0056 00086 (main.go:6) LEAQ ""..autotmp_16+80(SP), DI
0x005b 00091 (main.go:6) PCDATA $0, $-2
0x005b 00091 (main.go:6) LEAQ -48(DI), DI
0x005f 00095 (main.go:6) NOP
0x0060 00096 (main.go:6) DUFFZERO $277
0x0073 00115 (main.go:6) PCDATA $0, $-1
0x0073 00115 (main.go:6) LEAQ ""..autotmp_16+72(SP), AX
0x0078 00120 (main.go:6) MOVQ AX, ""..autotmp_15+208(SP)
0x0080 00128 (main.go:6) PCDATA $1, $1
0x0080 00128 (main.go:6) CALL runtime.fastrand(SB)
0x0085 00133 (main.go:6) MOVL (SP), AX
0x0088 00136 (main.go:6) MOVL AX, ""..autotmp_15+204(SP)
0x008f 00143 (main.go:8) LEAQ ""..autotmp_11+240(SP), DI
0x0097 00151 (main.go:8) XORPS X0, X0
0x009a 00154 (main.go:8) PCDATA $0, $-2
0x009a 00154 (main.go:8) LEAQ -32(DI), DI
0x009e 00158 (main.go:8) NOP
0x00a0 00160 (main.go:8) DUFFZERO $273
0x00b3 00179 (main.go:8) PCDATA $0, $-1
0x00b3 00179 (main.go:8) LEAQ type.map[int8]int(SB), AX
0x00ba 00186 (main.go:8) MOVQ AX, (SP)
0x00be 00190 (main.go:8) LEAQ ""..autotmp_15+192(SP), AX
0x00c6 00198 (main.go:8) MOVQ AX, 8(SP)
0x00cb 00203 (main.go:8) LEAQ ""..autotmp_11+240(SP), AX
0x00d3 00211 (main.go:8) MOVQ AX, 16(SP)
0x00d8 00216 (main.go:8) PCDATA $1, $2
0x00d8 00216 (main.go:8) CALL runtime.mapiterinit(SB)
0x00dd 00221 (main.go:8) NOP
0x00e0 00224 (main.go:8) JMP 423
0x00e5 00229 (main.go:8) MOVQ ""..autotmp_11+248(SP), CX
0x00ed 00237 (main.go:8) MOVQ (CX), CX
0x00f0 00240 (main.go:8) MOVBLZX (AX), AX
0x00f3 00243 (main.go:8) MOVQ AX, ""..autotmp_32+64(SP)
0x00f8 00248 (main.go:9) MOVQ CX, (SP)
0x00fc 00252 (main.go:9) NOP
0x0100 00256 (main.go:9) CALL runtime.convT64(SB)
0x0105 00261 (main.go:9) MOVQ 8(SP), AX
0x010a 00266 (main.go:9) XORPS X0, X0
0x010d 00269 (main.go:9) MOVUPS X0, ""..autotmp_24+160(SP)
0x0115 00277 (main.go:9) MOVUPS X0, ""..autotmp_24+176(SP)
0x011d 00285 (main.go:9) LEAQ type.int8(SB), CX
0x0124 00292 (main.go:9) MOVQ CX, ""..autotmp_24+160(SP)
0x012c 00300 (main.go:9) MOVQ ""..autotmp_32+64(SP), DX
0x0131 00305 (main.go:9) LEAQ runtime.staticuint64s(SB), BX
0x0138 00312 (main.go:9) LEAQ (BX)(DX*8), DX
0x013c 00316 (main.go:9) MOVQ DX, ""..autotmp_24+168(SP)
0x0144 00324 (main.go:9) LEAQ type.int(SB), DX
0x014b 00331 (main.go:9) MOVQ DX, ""..autotmp_24+176(SP)
0x0153 00339 (main.go:9) MOVQ AX, ""..autotmp_24+184(SP)
0x015b 00347 (<unknown line number>) NOP
0x015b 00347 ($GOROOT/src/fmt/print.go:274) MOVQ os.Stdout(SB), AX
0x0162 00354 ($GOROOT/src/fmt/print.go:274) LEAQ go.itab.*os.File,io.Writer(SB), SI
0x0169 00361 ($GOROOT/src/fmt/print.go:274) MOVQ SI, (SP)
0x016d 00365 ($GOROOT/src/fmt/print.go:274) MOVQ AX, 8(SP)
0x0172 00370 ($GOROOT/src/fmt/print.go:274) LEAQ ""..autotmp_24+160(SP), AX
0x017a 00378 ($GOROOT/src/fmt/print.go:274) MOVQ AX, 16(SP)
0x017f 00383 ($GOROOT/src/fmt/print.go:274) MOVQ $2, 24(SP)
0x0188 00392 ($GOROOT/src/fmt/print.go:274) MOVQ $2, 32(SP)
0x0191 00401 ($GOROOT/src/fmt/print.go:274) CALL fmt.Fprintln(SB)
0x0196 00406 (main.go:8) LEAQ ""..autotmp_11+240(SP), AX
0x019e 00414 (main.go:8) MOVQ AX, (SP)
0x01a2 00418 (main.go:8) CALL runtime.mapiternext(SB)
0x01a7 00423 (main.go:8) MOVQ ""..autotmp_11+240(SP), AX
0x01af 00431 (main.go:8) TESTQ AX, AX
0x01b2 00434 (main.go:8) JNE 229
0x01b8 00440 (main.go:8) PCDATA $1, $-1
0x01b8 00440 (main.go:8) MOVQ 336(SP), BP
0x01c0 00448 (main.go:8) ADDQ $344, SP
0x01c7 00455 (main.go:8) RET
0x01c8 00456 (main.go:8) NOP
0x01c8 00456 (main.go:5) PCDATA $1, $-1
0x01c8 00456 (main.go:5) PCDATA $0, $-2
0x01c8 00456 (main.go:5) CALL runtime.morestack_noctxt(SB)
0x01cd 00461 (main.go:5) PCDATA $0, $-1
0x01cd 00461 (main.go:5) JMP 0
... 省略不相关的部分
从编译结果中,我们可以看出map的迭代底层对应的是runtime.mapiterinit和runtime.mapiternext:
// mapiterinit initializes the hiter struct used for ranging over maps.
// The hiter struct pointed to by 'it' is allocated on the stack
// by the compilers order pass or on the heap by reflect_mapiterinit.
// Both need to have zeroed hiter since the struct contains pointers.
func mapiterinit(t *maptype, h *hmap, it *hiter) {
if raceenabled && h != nil {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiterinit))
}
if h == nil || h.count == 0 {
return
}
if unsafe.Sizeof(hiter{})/sys.PtrSize != 12 {
throw("hash_iter size incorrect") // see cmd/compile/internal/gc/reflect.go
}
it.t = t
it.h = h
// grab snapshot of bucket state
it.B = h.B
it.buckets = h.buckets
if t.bucket.ptrdata == 0 {
// Allocate the current slice and remember pointers to both current and old.
// This preserves all relevant overflow buckets alive even if
// the table grows and/or overflow buckets are added to the table
// while we are iterating.
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
// decide where to start
// 可以看出,map的迭代器会随机选择一个开始的bucket位置和开始的offset。
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket // 记录随机的开始位置。
// Remember we have an iterator.
// Can run concurrently with another mapiterinit().
if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
atomic.Or8(&h.flags, iterator|oldIterator)
}
mapiternext(it)
}
func mapiternext(it *hiter) {
h := it.h
if raceenabled {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiternext))
}
if h.flags&hashWriting != 0 {
throw("concurrent map iteration and map write")
}
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
checkBucket := it.checkBucket
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
// end of iteration
it.key = nil
it.elem = nil
return
}
// 判断是否正处于扩容搬迁中,对于正在搬迁过程中仍未完成搬迁的bucket,迭代过程中需要考虑进入旧的bucket里面。
if h.growing() && it.B == h.B {
// Iterator was started in the middle of a grow, and the grow isn't done yet.
// If the bucket we're looking at hasn't been filled in yet (i.e. the old
// bucket hasn't been evacuated) then we need to iterate through the old
// bucket and only return the ones that will be migrated to this bucket.
oldbucket := bucket & it.h.oldbucketmask()
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
if !evacuated(b) {
checkBucket = bucket
} else {
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
checkBucket = noCheck
}
} else {
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
checkBucket = noCheck
}
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
// TODO: emptyRest is hard to use here, as we start iterating
// in the middle of a bucket. It's feasible, just tricky.
continue
}
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.elemsize))
if checkBucket != noCheck && !h.sameSizeGrow() {
// Special case: iterator was started during a grow to a larger size
// and the grow is not done yet. We're working on a bucket whose
// oldbucket has not been evacuated yet. Or at least, it wasn't
// evacuated when we started the bucket. So we're iterating
// through the oldbucket, skipping any keys that will go
// to the other new bucket (each oldbucket expands to two
// buckets during a grow).
if t.reflexivekey() || t.key.equal(k, k) {
// If the item in the oldbucket is not destined for
// the current new bucket in the iteration, skip it.
hash := t.hasher(k, uintptr(h.hash0))
if hash&bucketMask(it.B) != checkBucket {
continue
}
} else {
// Hash isn't repeatable if k != k (NaNs). We need a
// repeatable and randomish choice of which direction
// to send NaNs during evacuation. We'll use the low
// bit of tophash to decide which way NaNs go.
// NOTE: this case is why we need two evacuate tophash
// values, evacuatedX and evacuatedY, that differ in
// their low bit.
if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) {
continue
}
}
}
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || t.key.equal(k, k)) {
// This is the golden data, we can return it.
// OR
// key!=key, so the entry can't be deleted or updated, so we can just return it.
// That's lucky for us because when key!=key we can't look it up successfully.
it.key = k
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
// The hash table has grown since the iterator was started.
// The golden data for this key is now somewhere else.
// Check the current hash table for the data.
// This code handles the case where the key
// has been deleted, updated, or deleted and reinserted.
// NOTE: we need to regrab the key as it has potentially been
// updated to an equal() but not identical key (e.g. +0.0 vs -0.0).
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue // key has been deleted
}
it.key = rk
it.elem = re
}
it.bucket = bucket
if it.bptr != b { // avoid unnecessary write barrier; see issue 14921
it.bptr = b
}
it.i = i + 1
it.checkBucket = checkBucket
return
}
b = b.overflow(t)
i = 0
goto next
}
小结一下,map的迭代顺序是完全随机的,并且map在迭代过程中会根据搬迁进度来判断是否要兼顾旧的bucket。
是否能在迭代过程中删除元素
这是一个比较热门的话题,即map中是否可以在迭代过程中删除元素。在不同语言中的行为结果可能是不一样的,熟悉C++的读者应该知道这样的行为在C++语言中是不合法的,本文讨论的是Go语言的行为:
import "fmt"
func main() {
m := map[int]int{
1: 1,
2: 2,
3: 3,
}
for k := range m {
if k == 1 {
delete(m, k)
}
}
fmt.Println(m)
}
在Go语言中,上述操作是允许且可以正确运行的。从上述map的删除分析中,我们可以看出,map的删除是找到对应的bmap删除key/value并且清空tophash,但是并不会导致下标产生偏移,因此该操作可以正常执行并得到预期的结果。
参考
总结
本文通过图示+源码的方式深度解析了Go语言核心数据结构map的工作原理。Go采用基于Hash散列算法的map实现,拥有优秀的时间复杂度。