![]()
Kubernetes的诞生不仅终结了容器编排的纷争,更带动了“云原生”理念的火热。作为CNCF核心项目的Kubernetes同时极大提升了CNCF本身的知名度。
CNCF与云原生
CNCF,全称Cloud Native Computing Foundation(云原生计算基金会),成立于2015年7月21日1。CNCF最初成立主旨是增强云原生应用和服务,使得所有开发者都能受益于开源技术。
This new organization aims to advance the state-of-the-art for building cloud native applications and services, allowing developers to take full advantage of existing and to-be-developed open source technologies. Cloud native refers to applications or services that are container-packaged, dynamically scheduled and micro services-oriented.
CNCF发展至今,其Landscape不断扩大,几乎包括软件开发的所有方面。
CNCF Landscape路线图分为十个步骤,每个步骤都是开发者在应用开发过程中需要思考的关键节点,它们分别是:
- 容器化(Containerization)
- 持续集成/持续部署(CI/CD)
- 编排和应用定义(Orchestration & Application Definition)
- 观测和分析(Observability & Analysis)
- 服务代理,发现和网格(Service Proxy, Discovery & Mesh)
- 网络,策略和安全(Networking, Policy & Security)
- 分布式数据库和存储(Distributed Database & Storage)
- 流和消息(Streaming & Messaging)
- 容器镜像中心和运行时(Container Registry & Runtime)
- 软件发布(Software Distribution)
CNCF托管的项目也与日俱进,以下是截止当前2021年4月的全景: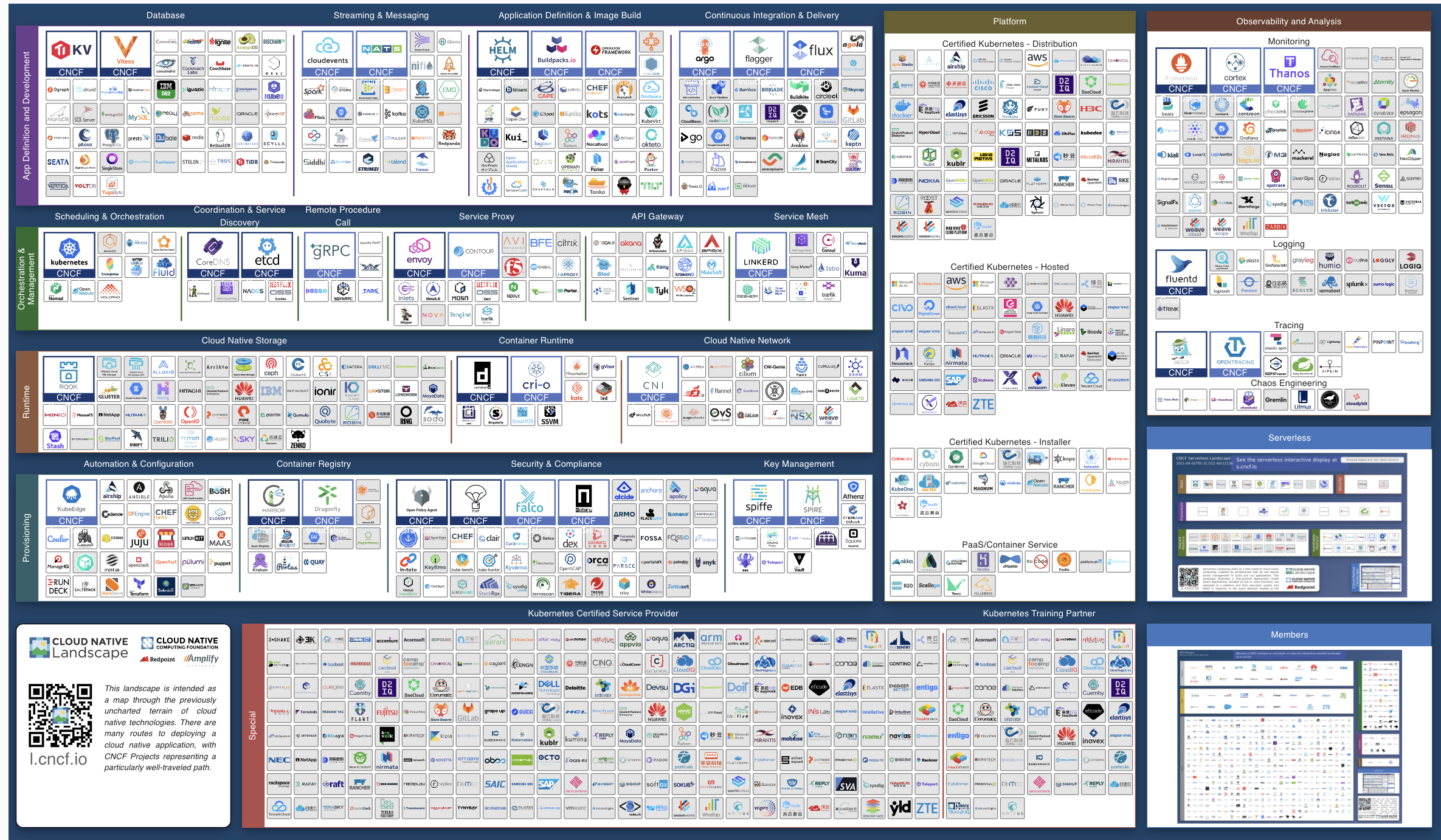
云原生是近年来极为火热的一个名词,但关于它本身的定义却逐渐从容器、微服务等具象的技术到云、弹性、容错、观测、管理等等抽象的概念。CNCF官方对于云原生的定义也会是与时俱进的,目前的版本描述如下:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
不过作为开发者来说,技术的定义不是关键,关键是它能解决什么样的问题。云原生对企业的思维习惯和开发模式有着深远的影响,相信在可见的未来中,云原生浪潮会持续向我们席卷而来!
容器技术的演进历史
提及Kubernetes就不得不提及容器技术。虽然现在大多数开发者了解容器是从Docker开始,但实际上容器技术并非由Docker创立,而是已经由来已久。
以下内容出自阿里云《云原生技术架构和实践》:
- 1979 年,Unix v7 系统支持 chroot,为应用构建一个独立的虚拟文件系统视图。
- 1999 年,FreeBSD 4.0 支持 jail,第一个商用化的 OS 虚拟化技术。
- 2004 年,Solaris 10 支持 Solaris Zone,第二个商用化的 OS 虚拟化技术。
- 2005 年,OpenVZ 发布,非常重要的 Linux OS 虚拟化技术先行者。
- 2004 年 ~ 2007 年,Google 内部大规模使用 Cgroups 等的 OS 虚拟化技术。
- 2006 年,Google 开源内部使用的 process container 技术,后续更名为 cgroup。
- 2008 年,Cgroups 进入了 Linux 内核主线。
- 2008 年,LXC(Linux Container)项目具备了 Linux 容器的雏型。
- 2011 年,CloudFoundry 开发 Warden 系统,一个完整的容器管理系统雏型。
- 2013 年,Google 通过 Let Me Contain That For You (LMCTFY) 开源内部容器系统。
- 2013 年,Docker 项目正式发布,让 Linux 容器技术逐步席卷天下。
- 2014 年,Kubernetes 项目正式发布,容器技术开始和编排系统起头并进。
- 2015 年,由 Google,Redhat、Microsoft 及一些大型云厂商共同创立了 CNCF,云原生浪潮启动。
- 2016 年 - 2017 年,容器生态开始模块化、规范化。CNCF 接受 Containerd、rkt 项目,OCI 发布 1.0,CRI/CNI 得到广泛支持。
- 2017 年 - 2018 年,容器服务商业化。AWS ECS,Google EKS,Alibaba ACK/ASK/ECI,华为CCI,Oracle Container Engine for Kubernetes;VMware,Redhat和 Rancher 开始提供基于Kubernetes 的商业服务产品。
- 2017 年 - 2019 年,容器引擎技术飞速发展,新技术不断涌现。2017 年底 Kata Containers 社区成立,2018 年 5 月 Google 开源 gVisor 代码,2018 年 11 月 AWS 开源 firecracker,阿里云发布安全沙箱 1.0。
- 2020 年 - 202x 年,容器引擎技术升级,Kata Containers 开始 2.0 架构,阿里云发布沙箱容器 2.0….
纵观整个容器技术的发展,最早期的技术萌芽也许只来自于一些局部的需求。但随着对“资源隔离”这一概念的逐步形成,容器技术越发完备。基于Linux Namespace+Linux Cgroups打造出的“沙盒运行环境”让容器逐步落地,并随着微服务理念的兴起和Docker对容器镜像的创新,最终迎来容器技术大爆发。
Kubernetes
Kubernetes的诞生不仅仅有技术因素,还与当时的容器编排商业格局息息相关。为了对抗Docker公司在容器编排领域主打的Docker Swarm和Mesosphere公司基于大数据领域资深经验的Mesos+Marathon,Google、CoreOS、RedHat等巨头联合推出了Kubernetes。
在随后的几年中,Kubernetes凭借自身先进的理念和背后强大的支撑,迅速将竞争对手击败,高举胜利旗帜。2017年10月,Docker公司宣布在Docker企业版中内置Kubernetes,就此终结容器编排纷争。
事实上,Kubernetes的架构设计并非凭空产生,而是来自于Google内部的基础设施架构Borg+Omega。Google自2000年初便开始使用Linux容器化技术,因此Kubernetes成功的背后,是一个已经经历十多年验证的可靠系统。
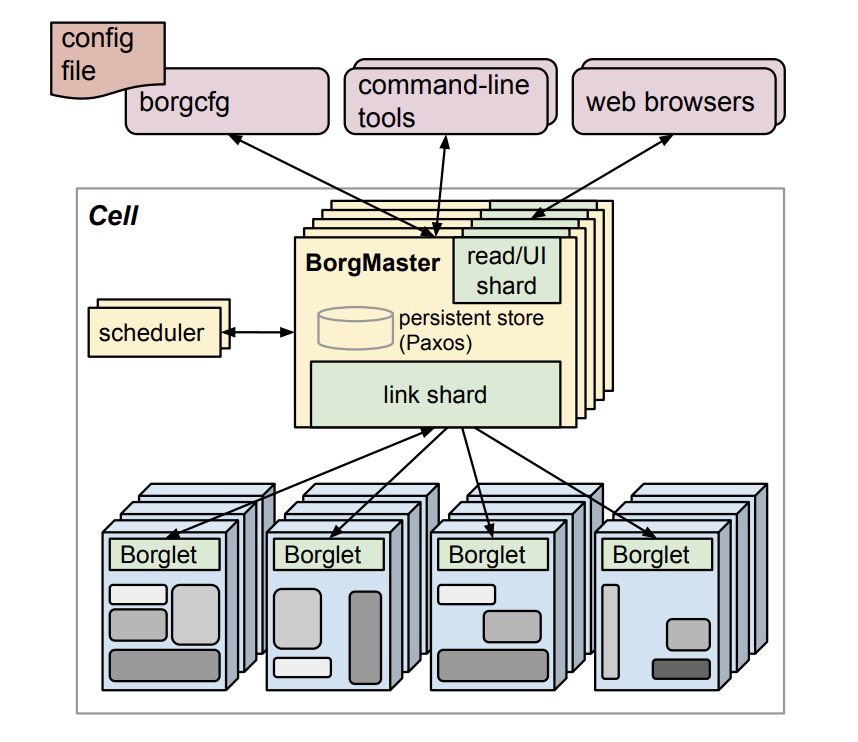
架构设计
Kubernetes的架构理念与Borg同源,也是C/S模型。主体上可以分成Control Plane和Compute Machine。
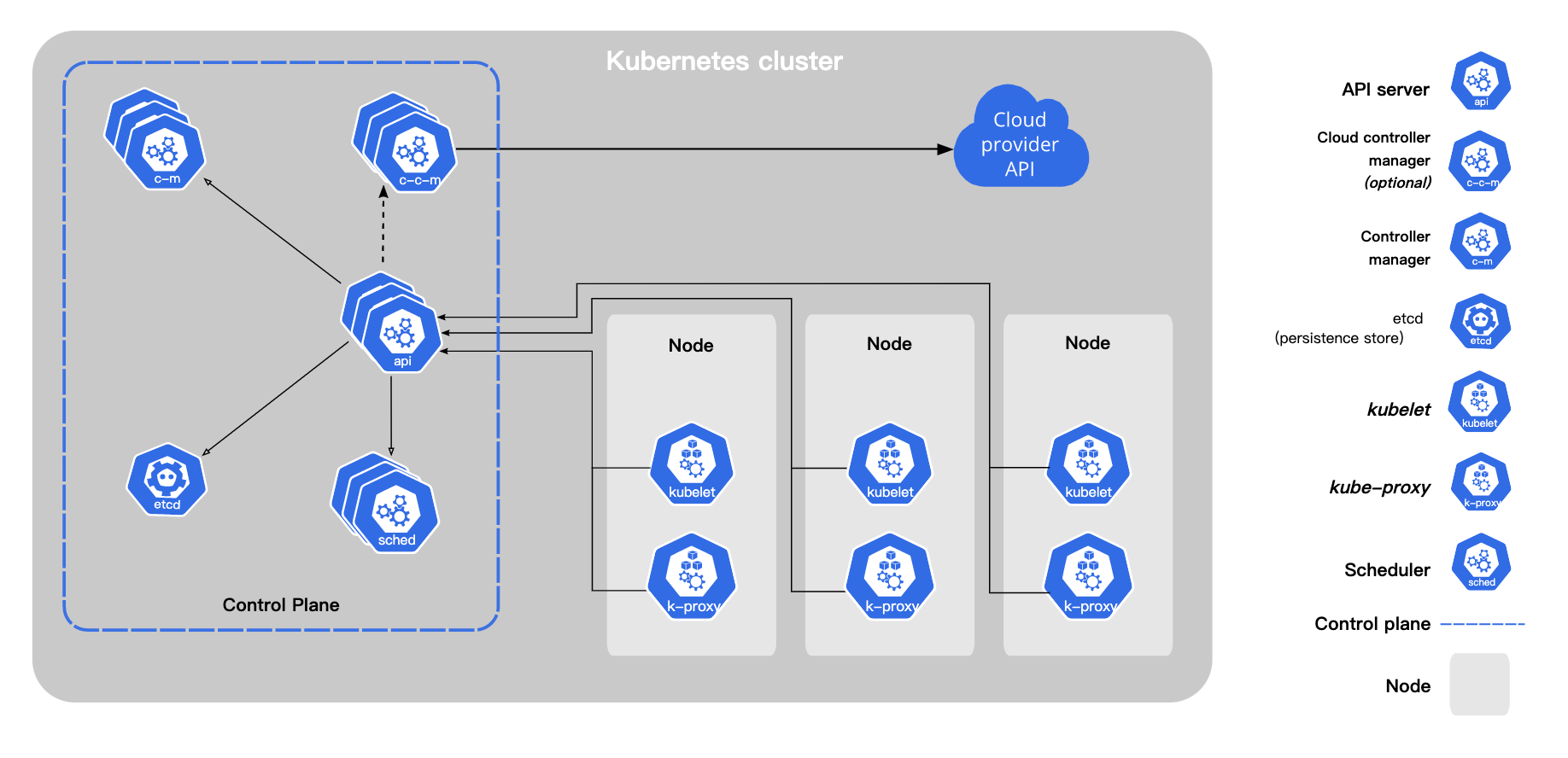
Control Plane包括如下核心组件:
- kube-apiserver:集群资源操作的唯一入口,创建与管理Kubernetes定义的核心对象。同时也包括认证、授权与访问控制。另一方面,暴露驱动整个Kubernetes集群工作的Watch接口。HA部署推荐多kube-apiserver实例,它们均对外提供服务能力。
- etcd:集群资源持久化存储,响应来自kube-apiserver的请求。基于Raft分布式共识算法保证数据的分布式强一致性。HA部署推荐etcd部署在独立集群中,三节点或五节点模式较佳。
- kube-controller-manager:运行集群核心的控制器组,诸如:Deployment、StatefulSet、DaemonSet、Job、Cronjob等等。HA部署推荐多kube-controller-manager,但其中只有Leader角色的节点对外提供服务。
- kube-scheduler:集群调度器,决策Kubernetes最小单元Pod和工作节点Node的绑定关系。HA部署推荐多kube-scheduler,但同kube-controller-manager一样,其中只有Leader角色的节点对外提供服务。
- cloud-controller-manager(可选):公有云上的扩展控制器组。
Compute Machine包括如下核心组件:
- kubelet:工作节点上的核心组件,跟CRI/CNI/CSI交互。另一方面,Kubelet会上报节点状态信息给API-Server,最终以助kube-scheduler决策调度。
- kube-proxy:工作节点上的核心组件,负责集群服务发现和负载均衡。
核心原理:声明式API
Kubernetes的核心原理之一:声明式API。声明式API并不少见,SQL便是典型的声明式API。所谓的声明式API,是指API描述了资源对象的某个最终状态,但API不描述如何达到这个最终状态。
Kubernetes广泛采用yaml文件来描述一个资源对象,以Nginx Deployment为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
以上是最为常见的Deployment资源对象声明。一方面,它描述了服务要基于nginx:1.14.2容器镜像运行,并且服务对外以80端口提供入口。另一方面,它还描述了服务要启动2个运行实例。从这个角度看,整个Deployment对象为Kubernetes集群描述了一个最终希望达到的状态,但并不关心Kubernetes最终通过何种手段完成。这,即是声明式API。
除了Deployment之外,Kubernetes还支持其它丰富的资源对象类型,例如:
- Pod
- Node
- Namespace
- StatefulSet
- DaemonSet
- Job
- CronJob
- ConfigMap
- Secret
- PersistVolume
- PersistVolumeClaim
- StorageClass
- Service
- IngressController
- …
更多核心Kubernetes对象定义详见:https://github.com/kubernetes/kubernetes/tree/master/pkg/apis(各子目录中types.go)
核心原理:控制器模式
Kubernetes的核心原理之二:控制器模式。如果说声明式API的存在是为了描述资源对象的最终状态,而不关心使用何种手段达到最终状态。那么控制器模式,便是指代一种通用的编程模型,提供可行手段让资源达到最终状态。
控制器模式简单概述来说,即通过一个控制循环,获取集群资源对象实际状态和预期状态的差异,再通过编排动作调整实际状态到期望状态。用代码表述来说,大致如下:
for {
actual := getClusterStatus()
expected := getUserYMLStatus()
if actual == expected {
continue
} else {
action()
}
}
同样以Deployment为例,在kube-controller-manager的源码如下(Kubernetes v1.20.0版本):
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
if !cache.WaitForNamedCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh) /*启动worker,进入控制循环*/
}
<-stopCh
}
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() { /*处理事件*/
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get() /*取出事件key*/
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string)) /*通过syncHandler来完成对事件的处理工作*/
dc.handleErr(err, key)
return true
}
// DeploymentController中的syncHandler
func (dc *DeploymentController) syncDeployment(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(context.TODO(), d, metav1.UpdateOptions{})
}
return nil
}
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef
// through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// List all Pods owned by this Deployment, grouped by their ReplicaSet.
// Current uses of the podMap are:
//
// * check if a Pod is labeled correctly with the pod-template-hash label.
// * check that no old Pods are running in the middle of Recreate Deployments.
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// Update deployment conditions with an Unknown condition when pausing/resuming
// a deployment. In this way, we can be sure that we won't timeout when a user
// resumes a Deployment with a set progressDeadlineSeconds.
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// rollback is not re-entrant in case the underlying replica sets are updated with a new
// revision so we should ensure that we won't proceed to update replica sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
可以看出,上述简化版代码和源代码的思路本质是一模一样的。并且实际对于Kubernetes来说,控制器模式从来都不是难点,真正难的地方是如何优化控制循环的性能,减少不必要的开销。Kubernetes解决该问题基于Informer机制:
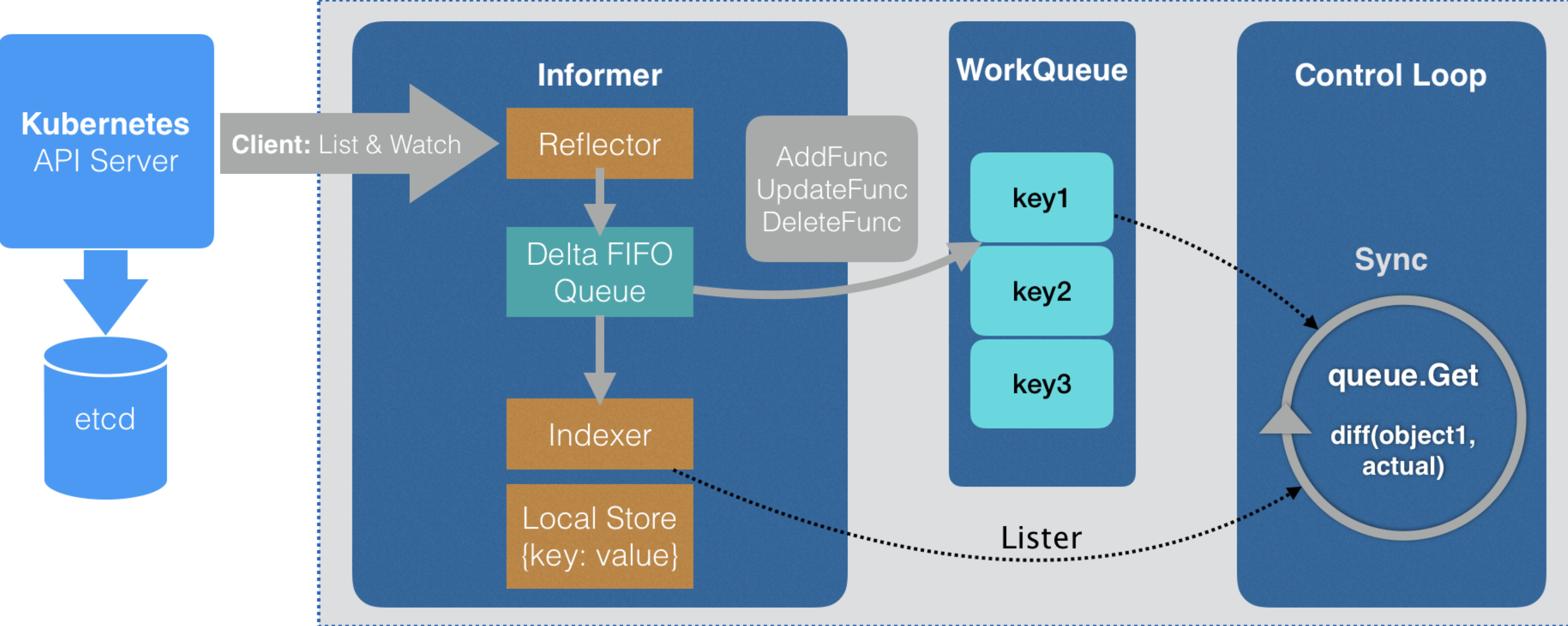
Informer机制的原理如下:
- 首先,集群资源状态的变化是通过kube-apiserver完成,持久化数据存储到etcd中。etcd的数据变更之后,通过gRPC stream将变更通知到kube-apiserver,此时如果存在某个控制器正在Watch该资源对象的变化,则会通过gRPC stream传输到客户端的Informer组件。
- 其次,Informer组件底层是一个名为Reflector的包,它调用kube-apiserver的ListAndWatch持续监听关心资源对象的变更。每当有新的变更通知,它会将通知事件放入Delta FIFO Queue。
- 接下来,Informe一方面通过注册的Handler事件将对象的Key加入工作队列,另一方面在本地创建索引和缓存。
- 最后,控制器本身的控制循环,会从工作队列中依次取出事件对象的Key,进行编排。
整体来看,Informer机制大大减少了控制器和kube-apiserver的交互,尤其是List这种昂贵的操作请求,极大减小集群整体压力。
进一步说,其实kube-controller-manager、kube-scheduler、kubelet、kube-proxy等组件都是通过不同资源对象的Informer建立与kube-apiserver的联系,从而完成整个集群的正常运转。如此看来,Kubernetes理解起来也并不困难。它不仅有着清晰的逻辑结构,而且该结构还非常简单。
是啊,优秀的系统架构往往不似想象中那么多弯弯绕绕,Kubernetes为我们展示了它的架构之美。
总结
本文简要介绍了CNCF、云原生与Kubernetes的诞生背景,回顾了近20年的容器技术发展史。同时向读者揭示Kubernetes的架构和其运行的两大核心原理:声明式API和控制器模式。
由此我们也可以看出,复杂的表面下往往蕴含着简单的原理。作为个人来说,我们无须惧怕,应当勇敢地前进去探索技术背后的真相。