前言
笔者在《从零开始学习RTC——音视频概述》的系列开篇文章中对音视频基础元素进行了简要概述。其中,笔者一笔带过了音视频数据在编码压缩之后的传输过程,然而这实际上涉及到了RTC服务端的技术架构。
目前最有名的RTC开源项目 WebRTC 很好展示了如何解决点对点之间的音视频通信,但实际业务场景中往往需要支持多方参会,例如:视频会议、在线课堂、直播连麦等等,此时WebRTC的扩展性就明显有了局限。
WebRTC
概述
什么是WebRTC?WebRTC的诞生和开源极大降低了实时通信的技术门槛,从而造就了一代又一代的音视频产品。2010年5月,Google以6820万美金收购了Global IP Solutions公司,从而拥有其编解码、回声消除、P2P等核心技术。Google随后于2011年5月开放了工程的源代码,并与IETF和W3C定制了行业标准,组成现在的WebRTC项目。

WebRTC主要包括:
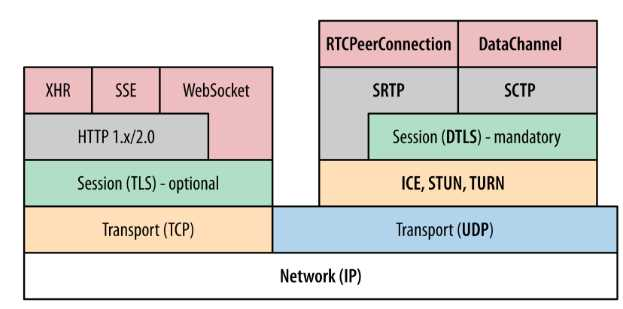
- 标准的协议栈,主要包括推荐用于信令交互的TCP协议栈和用于媒体数据传输的UDP协议栈。
- WebRTC C++实现和C++ Native API,可以用于开发者直接用在客户端App上面。
- 标准的JavaScript API,主要用于给浏览器直接使用。
WebRTC的设计初衷是让两个浏览器之间具备直接实时音视频通信的能力。因此一方面WebRTC中包含了音视频场景的核心技术,例如:编解码、回声消除、弱网对抗等;另一方面,WebRTC中还包含了完备的P2P技术,用来穿越企业数据中心网络中最常见的NAT。

局限
WebRTC通过信令服务器交换通信双方的基本信息,并通过P2P技术在通信双方建立直接的数据传输通道(PeerConnection)。WebRTC非常适合于两点之间的数据传输,并且在此基础上包括编解码、弱网对抗、音频引擎、视频引擎等完备的音视频能力。
那么,如果是三方通信呢?
在三方通信的场景下,如果两两之间都能够互相通信,则需要两两之间建立PeerConnection,因此总体需要建立如下的“三角关系”: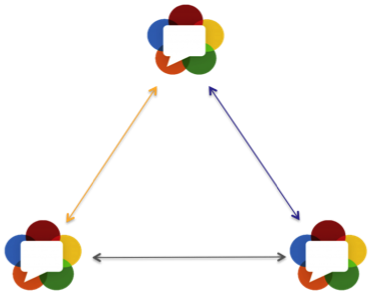
类似的,如果是五方通信呢?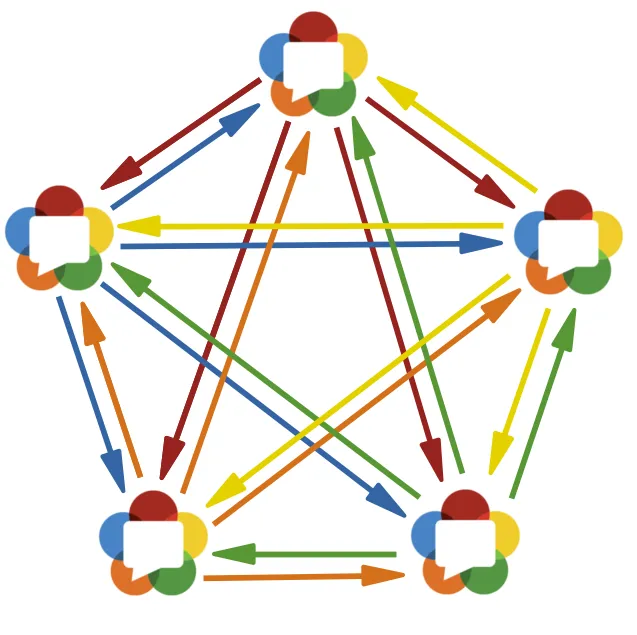
由此可见,随着参与通话的人数增多,基于WebRTC架构的通信模型复杂度将会大大增加,这样的Mesh结构显然是不具备可扩展性的。
企业级RTC服务架构
企业生产环境中的RTC服务器主要有两种形态——MCU和SFU。
MCU
MCU(Multipoint Control Unit)会使用中心化的节点与每个参会者保持一对一的连接。各发送方首先将自己的音视频流传输给MCU,再由MCU服务器将各路音视频流混合并转码,然后分别给每个参会者发送混合之后的音视频流。整体架构如下:
MCU在传统的多人会议中已经是比较成熟的架构,支持很多老旧设备。它也支持带宽自适应模式,因为混流单元可以为每个接收者生成不同质量的视频流。MCU可以充分利用硬件的解码能力,许多WebRTC客户端的芯片都具有解码单个视频流的能力。此外,由于MCU对于每个参会者来说,只有混合之后的音视频流,因此在网络传输上面比较节省带宽成本。
MCU的主要劣势是需要在服务端进行转码工作,会增大一定的延迟以及降低画质,同时混流会限制客户端的UI布局灵活性。
SFU
与此对应的另外一种架构是SFU(Selective Forwarding Unit),它会使用中心化的节点来直接转发参会者的音视频流。整体架构如下:
SFU服务端将不会参与任何转码工作,因此整体延迟小并且没有画质损失。通常SFU架构模式下,发送方需要支持生成一个流的多个版本(比如Simulcast或者VP8),SFU本身会根据客户端的带宽,动态调整发送不同清晰度的音视频流。
SFU的主要缺点是需要增加复杂的选流逻辑,对带宽的消耗也比较大。
不过总体来说,SFU的可扩展性比较强,是目前主流媒体服务器架构的首选。
总结
本文概述了RTC服务端架构的常见类型,阐述了WebRTC在服务端架构中的局限性以及企业级RTC的服务端架构。